產品管理 Scope Expansion without Commitment:當目標越來越大、資源越來越少 需求越來越大、資源越來越少——這不是正常的需求演進,是一種叫做 Scope Expansion without Commitment 的死亡螺旋。辨識三重紅旗,在被拖垮之前做出決定。
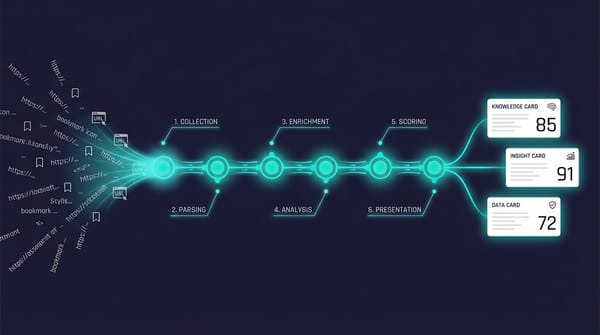
AI 你的 AI Agent 們需要一個共享大腦 — knowledge-pipeline 開源了 你的知識散落在每個 AI Agent 的 context window 裡,session 結束就消失了。knowledge-pipeline 是一條 6 層確定性管道,自動評分、路由、搜尋——零框架,純 Python,今天開源。
Claude Code 我用四個 AI 審計了一個 AI 工具——gstack telemetry 事件實錄 裝了一個 YC CEO 推薦的 Claude Code skill pack,兩週後發現它在記錄我的專案名稱。我用 Claude、Codex、Gemini、Perplexity 四個 AI 開了一場三方會議來審計它。
AI 記憶系統的三個工程取捨:Claude Code 的設計告訴我們什麼 Claude Code 的記憶架構設計揭示了三個工程取捨:索引層的維護成本、非同步濃縮的同步延遲、以及身份隔離的架構投入。沒有免費的午餐,關鍵是在你的場景下選對取捨。
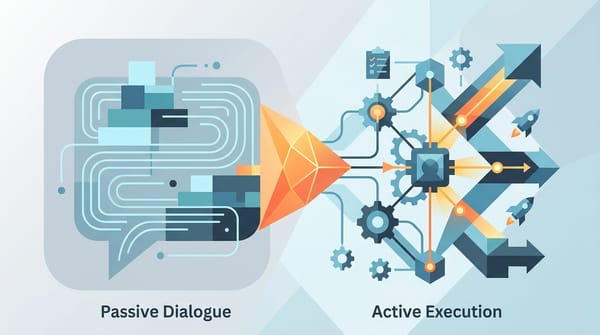
AI LLM 不該只會聊天:從被動對話到主動執行的工程化轉折 Claude Code Harness 重新定義了 LLM 在開發中的角色:從被動的代碼生成器,轉向主動的任務執行者——透過工程化的約束框架實現自主迭代。
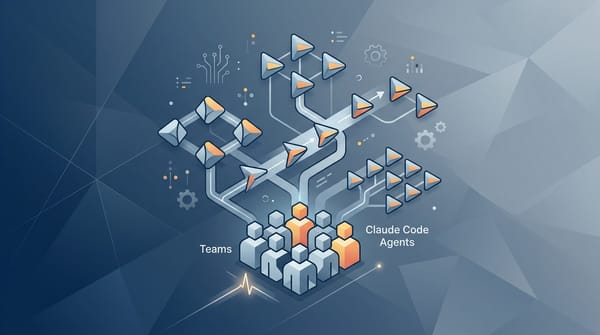
AI Claude Code 的多 Agent 編排,為什麼要從 Teams 開始想 Claude Code 的多 Agent 編排不該從「更聰明」開始想,而是從「如何分工協作」開始——oh-my-claudecode 用 Teams 模式解決的是複雜任務中的上下文和可控性問題。
AI 一場虛擬專家圓桌,讓 Rumelt、Grove、Meadows、Taleb 來批判我的系統 一位業界大佬用 AI 模擬了四位思想家來審視我的個人知識系統,四個完全不同的框架收斂到同一個核心問題:這個系統的產出,到底被消費了多少?
AI Issue tracking 的複雜度不是來自工具,是來自角色分工 Issue tracking 的複雜度問題不在工具,在於當初為彌補角色溝通鴻溝而設計的流程,如今反而成了負擔;AI Agent 時代改變了需求——從交接機制轉向共享上下文,但簡化帶來的可見性喪失需要謹慎權衡。