agent-memory 你的 AI agent 記憶系統,正在犯一個認知科學早就解決的錯誤 從三層記憶到四層認知架構。一場七位一體 Council 的設計決策記錄:為什麼你的 AI agent 記憶系統把事實和經驗混在一起處理是個 category error。
AI Claude Code 開發者建議:先問 codebase,再改碼 Claude Code 開發者 Boris 的實用階梯:先 codebase Q&A 再改碼;先計畫與自檢迴圈;用短 CLAUDE.md/MCP/企業設定共享脈絡;進階把 claude -p 當 Unix 工具、worktree 平行。
AI Agent Harness 入門:馬具、迴圈、三層記憶——以及為何還要 Eval Agent Harness 是駕馭無狀態 LLM 的控制層:組裝工作記憶、跑 tool loop、設停止條件。以 Hermes 本機三層記憶(技能/事實/情節)為案例,並補上多數框架仍缺的 tracing 與 eval。
AI Claude Code 為什麼有效:模型無狀態,狀態在執行環境 Claude Code 有效,是因為模型無狀態,狀態由 harness 組裝:工具 schema、系統提示、CLAUDE.md、skills 與權限。客製的是執行環境;開發重心轉向意圖表達與驗證審查,而非背誦神奇 prompt。
AI AI 加速的是軟體熵:用深度模組與戰略工程師救程式碼庫 AI 不只加速交付,也加速軟體熵。用深度模組、接縫、局部性與槓桿當共同詞彙,讓 agent 當戰術工兵、人當戰略工程師;先深化與測試防護網,再在遺留庫上放大 AI。
AI 密集 LM 的共識架構:Pre-norm、RMSNorm、SwiGLU——以及仍在變的長上下文 現代密集解碼器 LM 的架構已高度收斂:pre-norm、RMSNorm、無 bias、SwiGLU。這是穩定性與 GPU 效率的權衡,不是優雅理論。真正仍在變的是長上下文——GQA、滑動視窗與混合注意力。
AI 從 CLAUDE.md 到「做夢」:上下文工程如何把模型智力變成可用系統 模型變聰明不夠:要把智力變成可用系統,靠上下文工程。從 CLAUDE.md、Skills 漸進揭露、檔案系統式自主記憶,到生產級版本/並行/權限,再到頻外 Dreaming 鞏固跨 session 學習。
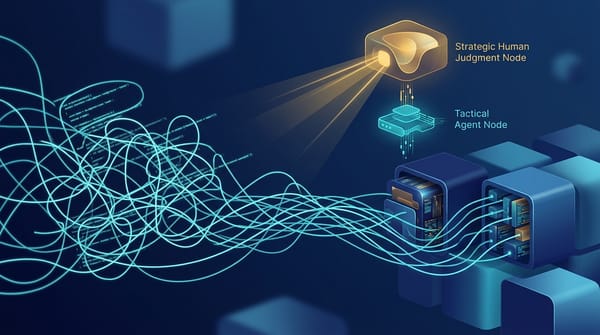
AI 高脈絡通才小隊:AI 時代工程開發的組織單元(不必消滅平台) 高脈絡通才小隊首先是工程開發執行單元:1~10 人共享系統心智模型,端到端實作與發布。平台/資安/設計系統不必消滅,應當積木與紅線護欄;法務等終審在循環外。AI 放大建造,不取代工程驗收。
AI 寫 code 快 100 倍之後:真正卡住的是整條鏈 Coding agent 讓寫軟體快 10 到 100 倍後,瓶頸從工程移到 PM、行銷、法務與設計。Andrew Ng 的組織答案是高脈絡通才小隊與樂高式建構模塊;企業則要由上而下重畫工作流、先整理資料再堆 agent。
AI 腦在雲、手可在你這:Claude Managed Agents 到底解決什麼 Claude Managed Agents 的重點不是多一個會聊天的 Claude,而是代理迴圈跑在託管側:腦在雲、手可在你這。本文拆 Messages API/Agent SDK/Managed 的自幹邊界、腦手解耦的好處與代價,以及何時該買 runtime、何時該留本機。
AI MCP 在 API 之上:模型如何發現工具,而不是背下每一個端點 MCP 不取代 API,而是疊在 API 之上,讓模型以標準方式發現工具與參數。從程式對程式的契約,走向模型對環境的語意層——代理保持輕量,能力可組合,權限仍須治理。
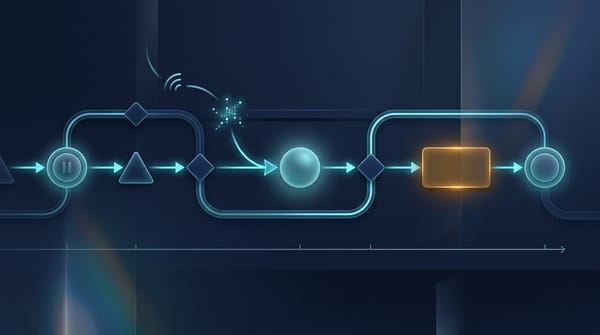
AI 長時程 Agent:休眠、檢查點與獨立評估 長時程 Agent 的工作單位是跨天工作流,不是單次提示詞。事件驅動休眠、逐步檢查點、獨立評估三角色,是讓報到、核貸、簽核類流程真正可恢復、可信賴的三塊骨頭。
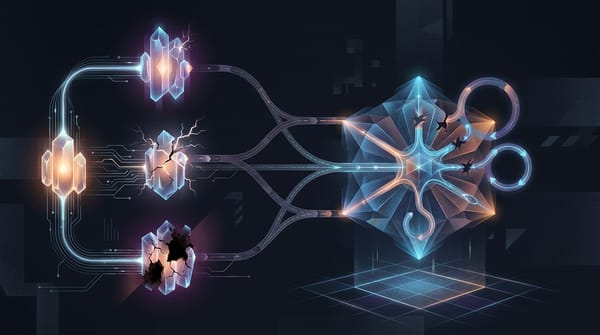
AI Agent 記憶不是一個向量庫:Session、State、Profile 與 Memory Bank Agent 記憶不是接一個向量庫就結束。把記憶拆成 Session、State、Profile、Memory Bank 四層,才能分清對話暫存、結構化中間結果、跨對話使用者事實,以及可語意檢索的長期經驗——也可治理、可忘記。
AI 從聊天框到本機執行:非工程師的 AI 飛輪 別再只把 AI 當聊天框。用「採訪你 → 建議打造什麼 → 本機經允許執行 → 更新心智模型」的 AI 飛輪,把痛點做成最小可用工具;搭配有用性護欄與權限習慣,非工程師也能安全跨過技術阻力。
AI 當實作不再是瓶頸:把「選擇與驗證」工程化 當 coding agent 讓實作成本驟降,組織的稀缺資源從「產出」變成「選擇與驗證」。從 Claude Design 的 Labs 方法論提煉可遷移判斷:原型與 PRD 的不確定性等級、feedback loop 工程化、以及為「差一點就能跑」下注的模型能力債。
AI 「你會不會寫代碼」已失重:當構建不再等於編程 「你會不會寫代碼」曾等同於有沒有資格把想法變成現實。現在構建≠編程:可執行 AI 把門檻從學機器語言,降到把事情說清楚。四步顧問循環、不可逆決策仍在人、個人規模第一次算得過來——普通人真正能構建的,是被經濟帳鎖住的那片可能性。
AI 掌控思想,而非代碼:Redis 作者 antirez 為何認為工程師不該再死盯程式碼 Redis 作者 antirez 重提「掌控思想,而非代碼」:當 AI 一次生成數千行,工程師若仍把價值綁在逐行寫與逐行審,影響力會被自己限縮。核心不是一句 prompt 出成品,而是用正確的 mental model、設計文件與測試驗證,去指揮 AI agent。
mk-brain 告別單體式 AI:為什麼多代理人架構是處理複雜任務的務實解法 當單一大模型開始被上下文膨脹與多步驟依賴拖慢,真正有效的解法往往不是塞入更長 prompt,而是把任務拆成多個特化代理協作。多代理架構不是噱頭,而是讓 AI 系統在複雜場景中維持效率、可預測性與可維護性的務實路徑。
mk-brain AI Agent 的下一步:為什麼標準化知識格式 (OKF) 是企業導入的最後一哩路 當 AI Agent 要從聊天機器人進化為能處理複雜業務的數位員工,關鍵已非模型本身,而是如何讓它穩定存取、理解並信任企業知識。Google Cloud 推出的 Open Knowledge Format (OKF) 正是為了解決這個問題,它試圖建立一套 AI 時代的知識基礎設施,讓數據的共享、授權與調用都有標準可循。
mk-brain 當 AI 寫下 90% 的程式碼:工程團隊的競爭力,正從個人產出轉向系統設計 Anthropic 內部高達 90% 的程式碼由 AI 產出,這不僅是生產力工具的勝利,更是工程組織轉型的信號。當 AI 成為主力開發者,人類工程師的角色將從「寫」程式轉向「設計與審查」系統。未來的競爭優勢,將取決於誰能建立更高效、更安全的 AI 協作流程與自動化護欄。
mk-brain 單一模型的神話終結:從 Fable 5 事件看多模型編排的務實轉向 「單一模型就能解決所有問題」的時代已經過去了。Anthropic Fable 5 的回歸,看似是產品更新,實則揭示了 AI 產業的深層轉變:即使是頂尖模型,也面臨著成本、安全與效能的限制。這篇文章將帶你深入探討,為何開發者正從對單一模型的迷信,轉向更精巧、更具成本效益的「多模型編排」策略,以及這對未來的 AI 產品設計意味著什麼。
mk-brain AI Agent 的未來:從提示詞工程到系統架構的思維轉變 關於 AI agent 的討論,正從提示詞工程的迷思中解放,轉向更為根本的系統架構。打造一個真正有效的 AI agent,關鍵不在於提示詞寫得多麼精巧,而在於能否將記憶、工具、執行循環與觀測機制,組合成一個穩定且可擴展的模組化系統。這種從「語言」到「架構」的思維轉變,是我們能否建構出可靠、可預測的自主系統的核心。
mk-brain 模型 Tool Call 的失靈模式有家族性,這如何改變我們對 Agent 可KO性的診斷框架? 當 AI Agent 的工具調用(Tool Call)失敗時,我們常視為隨機錯誤。但近期實驗揭示,這些錯誤模式其實帶有「家族特徵」,與模型系出同源。這意味著,修復工具的有效性,取決於它與特定模型「家族」的錯誤模式是否匹配。本文將探討如何從單點修補,轉向建立一套系統性的診斷框架,打造真正可維護的 AI 系統。
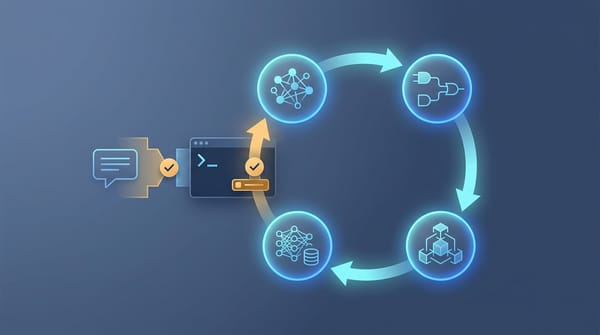
mk-brain AI 的演進之路:為何持續學習需要超越模型權重的三層架構 AI 的「持續學習」不該只停留在模型微調,因為這條路徑既昂貴又充滿「災難性遺忘」的風險。想打造能真正落地、不斷進化的智慧體?本文將揭示一個超越模型權重的三層演進架構:模型、框架與上下文。了解如何整合這三者,讓你的 AI 系統像生命體一樣,持續累積經驗、自我成長。
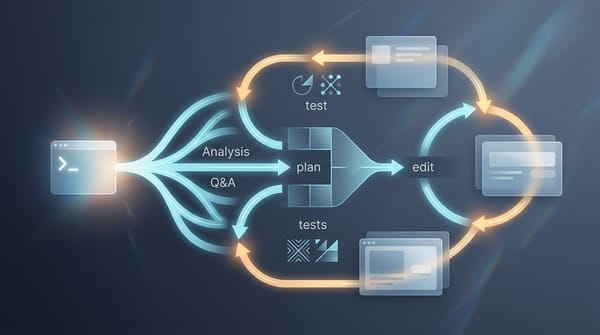
mk-brain AI IDE 的下個戰場:從程式碼生成,走向可重用的工程流程 AI 開發工具的競爭正在質變。過去我們關注程式碼生成的速度與品質,但 Kiro IDE 的更新揭示了新戰場:將分析、規劃、拆解等軟體工程前期工作,轉化為可自動執行、可重用的工作流程。這不只是工具的演進,更是開發者角色與價值的重新定義。