你的 AI Agent 們需要一個共享大腦 — knowledge-pipeline 開源了
你的知識散落在每個 AI Agent 的 context window 裡,session 結束就消失了。knowledge-pipeline 是一條 6 層確定性管道,自動評分、路由、搜尋——零框架,純 Python,今天開源。

你是不是也這樣?
每天在 Claude、ChatGPT、Gemini、Codex、Grok 之間來回切換。問 Claude 查過的東西,Gemini 不知道。讓 Codex review 過的判斷,下一個 session 的 Claude 也不記得。
收藏了幾百個 URL,但它們只是靜靜躺在書籤裡等死。
這就是多 Agent 時代最被忽略的問題:你的知識散落在每個 Agent 的 context window 裡,session 結束的那一刻就消失了。
不是又一個 RAG
市面上已經有很多「丟文件進向量庫,然後搜尋」的工具。它們解決的是「找到東西」的問題。
但我面對的問題不是找不到——是太多東西,不知道哪些值得花時間。
所以我花了幾個月,打造了一條不一樣的知識管道。它不只幫你存東西,它會主動告訴你每則知識值多少分、該怎麼處理。
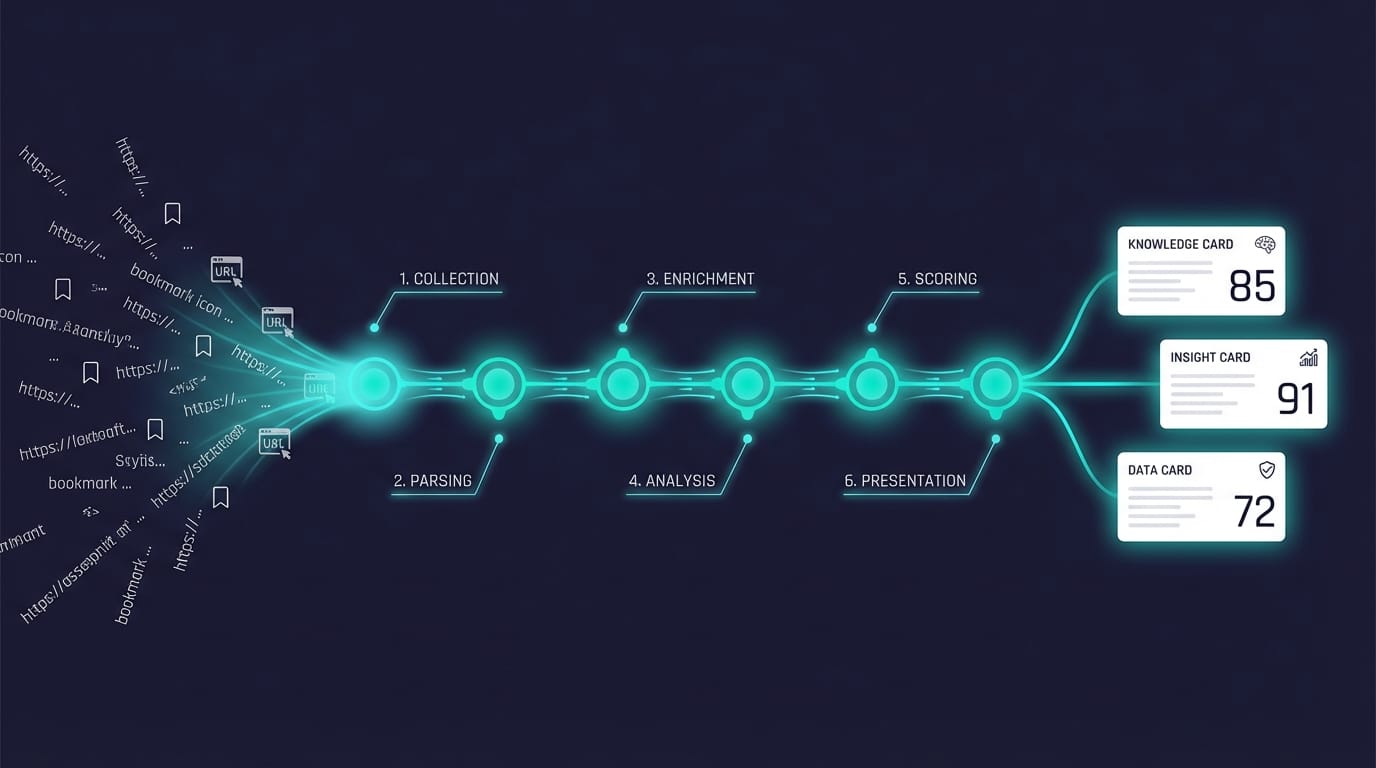
6 層確定性 Pipeline
URL → Ingest → Enrich → Score → Embed → Search → Serve
↓
signal=91, route=writer
"這篇論文提出了全新的 agent 設計框架..."
每一層做一件事,可以獨立跑、獨立測試、獨立替換:
- Ingest — URL 匯入,自動清除 tracking 參數、去重
- Enrich — 全文抓取 + LLM 摘要(一句話核心洞察)
- Score — 8 個維度的 LLM 評分 + 自動路由
- Embed — bge-m3 dense + sparse 雙向量
- Search — 混合語意搜尋 + cross-encoder reranking
- Serve — HTTP API,任何 AI Agent 都能查
8 維度評分:不是「相關不相關」,是「值多少分」
這是整個系統最核心的部分。每則知識會被 LLM 打上 8 個維度的分數(0-5):
| 維度 | 衡量什麼 |
|---|---|
| knowledge_density | 資訊密度,是否有可複用的框架 |
| novelty | 新穎度,是否提出新觀點 |
| evidence_strength | 證據強度,有數據還是純猜測 |
| actionability | 可行動性,讀完能不能立刻做事 |
| risk_level | 風險等級,涉及的技術/社會風險 |
| time_horizon | 影響時間,short / mid / long |
| emotional_noise | 情緒噪音,標題黨還是有料 |
| source_credibility | 來源可信度,論文還是匿名貼文 |
這些分數會合成一個 signal score(0-100),然後自動路由:
- writer — 高密度 + 強證據 → 適合寫成文章
- research — 高新穎度 → 需要更深入調查
- action — 高可行動性 → 可以立刻執行
- validator — 高風險或高情緒 → 需要事實查核
- archive — 低優先級 → 歸檔
舉個實際例子:
[91] [writer] LLM Powered Autonomous Agents - Lil'Log
→ 知識密度 5, 新穎度 3, 證據 4, 來源可信度 4
[58] [archive] The PARA Method - Forte Labs
→ 知識密度 3, 新穎度 2, 證據 2, 來源可信度 3
同樣是「知識管理」主題的文章,Lil'Log 的技術深度文拿到 91 分被路由到「寫文章」,PARA 方法論拿到 58 分被歸檔。不是所有知識都值得你花同樣的時間。
為什麼是零框架
沒有 LangChain。沒有 LlamaIndex。沒有任何 AI 框架。
整個系統只依賴兩個 pip 套件:numpy 和 FlagEmbedding。其餘全部是 Python 標準庫。
為什麼?因為框架是知識管道最大的敵人。
當你的知識系統依賴一個每週更新、API 不斷變動的框架,你花在維護框架相容性的時間會超過花在知識管理本身的時間。一條知識管道應該像水管一樣穩定——你打開水龍頭,水就流出來。不需要每週更新水龍頭的 firmware。
為什麼是 Ollama First
預設 LLM 後端是本地 Ollama,不需要任何 API key。
原因很簡單:如果你已經在用多個 AI Agent,你很可能也在跑地端模型。而且知識評分是一個每天都要跑的批次任務,用 API 的成本會快速累積。
當然,如果你想用 OpenAI 或 Anthropic,改一行 .env 就行——任何 OpenAI-compatible API 都支援。
30 秒 Quickstart
git clone https://github.com/MakiDevelop/knowledge-pipeline.git
cd knowledge-pipeline
bash quickstart.sh
不需要安裝 Ollama,不需要下載模型。Quickstart 會載入預評分的示範資料,讓你立刻看到評分和路由的效果。
想接上你自己的 LLM?
pip install -r requirements.txt
ollama pull qwen2.5:7b
cp .env.example .env
python3 ingest.py https://your-favorite-article.com
python3 enrich.py
python3 score.py
python3 search.py "AI agents"
給你的 AI Agent 一個共享大腦
啟動 API server:
python3 serve.py
然後任何 Agent 都能查:
GET http://localhost:8780/search?q=AI+agent+orchestration&k=5
回傳帶有 signal score 和路由的結果。你的 Claude 可以知道你上週讓 Gemini 評估過的那篇論文拿了 91 分。你的 GPT 可以知道你之前標記為「需要事實查核」的那則消息。
知識不再隨著 session 消失。它活在一個所有 Agent 都能存取的共享層裡。
開源,歡迎貢獻
MIT License,GitHub 上已經開了 5 個 good first issues:
- RSS feed 匯入
- Obsidian vault 掃描
- CSV 匯出
- Docker Compose 一鍵啟動
- Web 搜尋介面
如果你也受夠了知識散落在各個 AI Agent 裡,歡迎 star、fork、PR。
GitHub → github.com/MakiDevelop/knowledge-pipeline
我是江中喬(Maki),在 91APP 做 AI PoC,之前在痞客邦當產品總監。我的日常就是在各種 AI Agent 之間協作,這個工具是我自己每天在用的知識基礎設施。如果你對多 Agent 協作、個人知識管理、或 AI 工程有興趣,歡迎在 LinkedIn 上找我聊。