AI 寫程式,為何同個模型表現天差地遠?關鍵在 LLM 之外的「外殼」設計
我們常以為 AI 寫程式的能力完全取決於底層的大型語言模型,但為何同樣是 GPT-4 或 Claude 3,在不同工具中的表現卻有雲泥之別?本文將深入探討決定 AI Agent 效能的關鍵——那層圍繞著 LLM 的「外殼」架構,以及它如何成為未來軟體工程的新戰場。

最近在不同的開發環境中切換,我越來越常感覺到一個現象:同樣是基於 GPT-4 或 Claude 3 Opus 這類頂尖的大型語言模型(LLM),在 A 工具中它像個資深架構師,能精準地理解我的意圖並產出高品質程式碼;換到 B 工具裡,卻退化成一個只會依樣畫葫蘆的初階實習生。這種表現上的巨大落差,一度讓我以為是提示工程(Prompt Engineering)的細微差異所致,但深入探究後,我發現真正的答案藏在更深層的系統設計中。
問題的核心,並不在於 LLM 本身,而在於那層圍繞著它的「外殼」——一個在 AI 圈內逐漸被稱為「Harness」的系統。這層外殼決定了 AI Agent 究竟是個能動手解決問題的得力助手,還是一個空有理論的清談家。而打造這層外殼的工藝,也就是「Harness Engineering」,正快速成為軟體工程師在 AI 時代的新主戰場。
重新定義 AI Agent:不只是 LLM,更是「LLM + Harness」
過去我們談論 AI Agent,焦點往往集中在它使用了哪個 LLM。但一個更精確的公式應該是:Agent = LLM + Harness。LLM 是大腦,負責思考、推理與生成;Harness 則是賦予大腦感知與行動能力的軀幹與四肢。它是一個完整的系統,提供上下文、工具、執行權限與回饋機制,讓 LLM 的智能得以在真實世界中落地。
這個週末,我動手用 C# 和 Microsoft 的 Agent Framework 搭建了一個小型的多代理人實驗室,其中包含編碼(Coder)、審查(Reviewer)和資安(Security)三個角色。這個過程讓我深刻體會到,真正的挑戰不在於挑選哪個 LLM,而在於如何為這些 LLM 打造一個高效的協作與執行環境。
如果沒有設計精良的 Harness,即使最強大的 LLM 也如同一個被關在暗房裡的天才,有絕頂智慧卻無從施展。像 Cursor 或 Anthropic 為 Claude 設計的原生編碼環境之所以強大,正是因為它們在 Harness 層級下了極深的功夫,而不僅僅是做一個模型的 API 封裝。
拆解 Harness 的四層關鍵架構
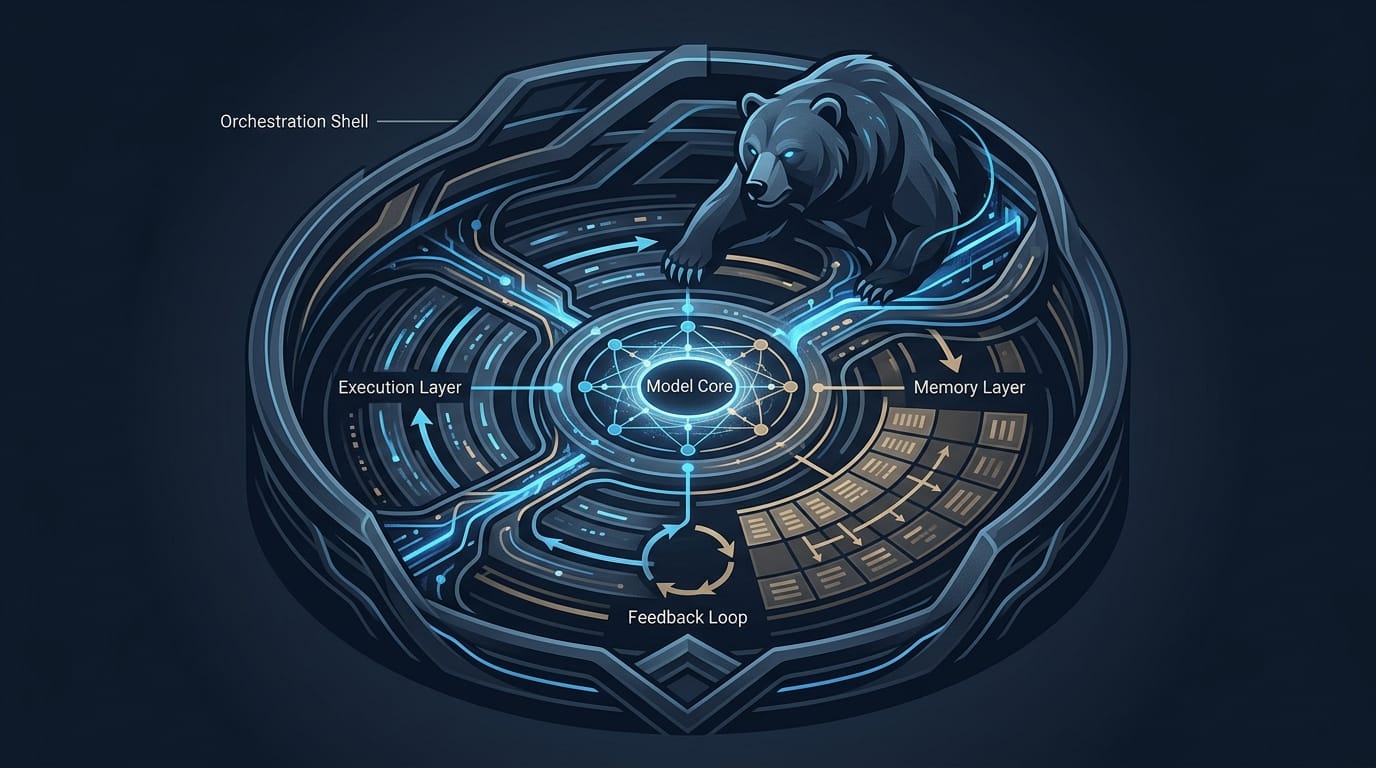
一個成熟的 Harness 系統,大致可以拆解為四個相互協作的層次。這四層架構的完整度與精細度,直接決定了 AI Agent 的最終效能,也是造成不同 IDE 或工具之間表現差異的根本原因。
執行層(Execution Layer):賦予 AI Agent 實際操作的能力。 這是賦予 LLM「雙手」的一層,提供了一個安全的沙盒環境,讓 Agent 能夠實際執行指令,例如讀寫檔案、執行 shell 命令、呼叫 API,或與版本控制系統互動。沒有執行層,Agent 只能「建議」程式碼,而無法將其寫入檔案、安裝依賴套件或運行專案。這正是從「紙上談兵」到「動手實作」的關鍵一步。
記憶層(Memory Layer):打造 AI Agent 的「長期記憶」與「情境感知」。 這層的作用遠不止於儲存對話歷史記錄。一個強大的記憶層會自動將專案的程式碼規範、架構文件、API 文件等關鍵資訊,以「Skills」或「Rules」的形式注入到 Agent 的工作情境中。這讓 Agent 在編寫程式碼時,能遵循專案既有風格,而不是每次都從零開始猜測,有效解決了 LLM 最為人詬病的「金魚腦」問題。
反饋層(Feedback Layer):建立 AI Agent 的「行動-觀察-修正」循環。 這是給予 LLM「感官」的一層。當 Agent 透過執行層寫完一段程式碼後,反饋層會自動觸發測試、Linter 或編譯器,並將結果(無論是成功訊息還是錯誤堆疊)回傳給 Agent。這個關鍵機制讓 Agent 能夠自主發現並修正錯誤,進行迭代式的開發,從而大幅提升程式碼的交付品質。
編排層(Orchestration Layer):AI Agent 團隊的「專案經理」。 作為 Harness 的最高層,編排層扮演著專案經理的角色。當收到一個複雜的開發需求時(例如「建立一個具備 JWT 驗證的登入 API」),它會負責將這個大任務拆解成一系列更小、可執行的子任務,並依序分配給底層的 Agent。此外,編排層也負責協調多個 Agent 之間的合作(如 Coder 完成後交由 Reviewer 審查),並設計防呆機制,避免 Agent 陷入無限的錯誤修正迴圈,確保整個開發流程順暢高效。
從工具選擇到系統設計:Harness 思維的實務意義
理解了 Harness 的四層架構後,我們看待 AI 編碼工具的視角也應該隨之轉變。這不再是一個關於「哪個模型比較聰明」的單純問題,而是一個關於「哪個系統設計得更完整」的工程問題。
我們評估 AI 編碼工具的標準,不應再只看它用了哪個版本的模型,而應該檢視其 Harness 的成熟度:它能多大程度地理解專案上下文(記憶)?它能自主執行與測試嗎(執行與反饋)?它能將複雜任務拆解並管理流程嗎(編排)?
對於企業或團隊而言,無論是選擇導入外部工具,還是著手建構內部的 AI 開發平台,Harness 思維都提供了極具價值的評估框架。這意味著我們需要將關注點從模型本身,轉移到整個系統的整合度與自動化流程上。一個具備強大 Harness 的系統,即便搭配的是次一級的 LLM,其綜合表現也可能遠勝於一個只對頂級 LLM 做了簡單封裝的「空殼」工具。
LLM 的能力邊界正在被快速推高,模型本身正逐漸成為一種可替換的基礎設施。真正的差異化優勢,將體現在如何圍繞這些強大的「大腦」建立起高效、可靠的執行與協作系統。對於軟體工程師來說,學習如何設計、建構和優化這些 Harness,將是未來幾年內提升自身價值、駕馭 AI 浪潮的核心技能。
延伸閱讀
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。