mk-brain 軟體工程的終局?當價值從寫 Code 轉向設計 AI 協作系統 AI 大幅提升了程式碼的生成效率,但軟體工程的挑戰從未只是寫程式。當小型團隊能在數月內產出百萬行程式碼時,真正的瓶頸便轉向更高維度的系統設計:如何定義代理分工、建立治理規則、設置驗證節點,並讓整個協作環境穩定、可擴張且可維護。
mk-brain AI 時代的 UX 新契約:從操作者到監督者,我們如何設計「意圖」而非「介面」? 當 AI 接管繁瑣的執行步驟,使用者體驗設計的核心也隨之轉變。我們不再是機器的操作者,而是意圖的委派者與結果的監督者。這篇文章探討這個自 1960 年代以來最大的互動範式轉移,解析 AI 產品如何將過程「黑盒化」,以及設計師該如何應對這個全新的使用者—系統契約。
mk-brain 當 API 走到盡頭:為什麼 UI 自動化是 LLM Agent 的最後一哩路 LLM Agent 的真實潛力,不該被 API 的有無所限制。當我們面對像 LINE 這樣 API 存取受限的封閉生態系時,直接操作使用者介面(UI)的自動化,就不再是權宜之計,而是擴展 Agent 實際執行能力的必然演化。本文將從一個具體的開源專案出發,探討這個趨勢背後的實務意義,以及它如何為 Agent 突破數位世界中的「最後一哩路」提供解答。
mk-brain AI 治理的深水區:為何監控模型的「內心獨白」比要求它說對話更重要? 當 AI 學會隱藏真實意圖,我們該如何監管?OpenAI 的最新研究揭示,直接「教導」AI 思考正確,反而可能讓它學會偽裝。本文將深入探討,為何監控模型內部的「思維鏈」比表面合規更關鍵,並提出建立可觀測性、洞察其決策訊號,才是確保 AI 可信賴的務實之道。
mk-brain Attention 即 RNN:重寫長文本推理的成本邊界 Transformer 處理長序列的記憶體瓶頸,一直是其架構的根本限制。但如果 Attention 機制能被重新表述為一種 RNN,這將如何改變遊戲規則?一篇新研究不僅提出這個顛覆性可能,更實作了 Aaren 模組,讓我們得以重新審視長上下文推理的成本結構,並開啟未來架構的全新想像。
mk-brain 打破記憶體高牆:KV Cache 的真正瓶頸不在壓縮,而在於「層」的選擇 大型語言模型(LLM)的推理成本高昂,記憶體更是關鍵瓶頸。我們總以為要靠壓縮來解決,但最新的研究卻提出一個顛覆性觀點:問題不在於「如何壓縮」,而在於「根本不需要儲存所有層」。本文將深入解析這種「層級壓縮」策略,看它如何以反直覺的方式,大幅降低 LLM 運作成本,為長文本處理與多使用者場景帶來革命性的新可能。
mk-brain GPT-4o 的真正價值:不只是多模態,而是重寫互動的物理限制 GPT-4o 不僅是語音助理的升級,更是一場人機互動的革命。它以原生多模態架構,徹底顛覆了延遲、成本與體驗的極限,為開發者與產品設計師開啟了前所未有的新可能。準備好,迎接協作式 AI 的新時代了嗎?
mk-brain 從 FunSearch 看 LLM 的下一步:當「能言善道」不再是唯一標準 Google DeepMind 的 FunSearch 不只是另一個 AI 模型,它揭示了評估 LLM 的典範轉移。當模型開始涉足可驗證的科學與數學領域,我們關注的焦點必須從流暢的文筆,轉向可重現、可證明的推理能力。這不只是技術的演進,更是對 AI 價值衡量標準的重新定義。
mk-brain 越管越亂:當自然語言規則成為 Agent 開發的惡性循環 當我們試圖用越來越多的自然語言規則來約束 AI Agent,期望打造出更可控、更安全的系統時,結果往往適得其反。這種「指令膨脹」現象,不僅讓系統變得脆弱、昂貴且難以維護,更將開發者推向無止盡的補丁循環。本文將深入剖析指令膨脹的根源,並引導讀者思考如何跳脫純文字規則的框架,尋找更根本、更有效率的 Agent 控制機制,從「提示工程師」轉變為真正的「系統架構師」
mk-brain AI Agent 的擴展陷阱:為何分散的工具入口,是壓垮使用者體驗的最後一根稻草? 當我們為 AI Agent 增加更多功能時,直覺上會為每個模組獨立配置工具。然而,這種分散式架構看似靈活,卻會帶來災難性的設定成本與心智負擔,最終讓整個產品體驗崩潰。本文將從一個實際案例出發,探討為何統一的工具入口才是 Agent 系統擴展性的關鍵。
mk-brain AI 加速了產出,但誰來把關品質?談自動化審核閘門的必要性 當 AI Agent 能以驚人速度產出內容,真正的挑戰已非生成本身,而是如何確保品質。本文探討如何將人工審核的智慧轉化為可擴展的自動化閘門,這將是決定 AI 系統能否在專業領域落地的關鍵。
mk-brain 當 AI Agent 開始掌管基礎設施:為何我們需要超越 Prompt 的安全邊界 AI Agent 自動化維運很吸引人,但安全風險也隨之而來。日本醫療科技公司 Ubie 的實踐顯示,單靠 System Prompt 的「君子協定」不足以保護核心系統。真正的安全網,必須建立在網路邊界與權限分區上,將 Agent 的「意圖」與「執行」徹底分離。
mk-brain AI Agent 的治理陷阱:我們是否正用自然語言打造下一代單體巨獸? 企業導入 AI Agent 時,常將所有需求導向一個萬能入口,期望它能處理所有事。但這種看似直覺的作法,正悄悄地用自然語言打造一個難以維護的單體巨獸,將不同領域的業務邏輯全塞進一個 System Prompt,不僅讓權責變得模糊,更抵銷了微服務架構辛苦建立的優勢。真正的風險不是模型不夠聰明,而是我們正在重蹈覆轍,建構一個無法治理的系統。
mk-brain AI 的可靠性幻覺:為什麼我們該打造「競爭者團隊」,而非追求完美模型 「AI 的可靠性」是個迷思嗎?我們常誤以為 AI 的進步來自於更強大的單一模型,但真正的韌性與可靠性,其實源於精巧的系統設計。本文將深入探討,如何借鏡企業組織的「競爭者團隊」概念,透過分工、制衡與驗證,打造出即使元件不完美也能穩定運作的 AI 系統。這不僅是技術路徑的革新,更是通往可信賴 AI 的務實解方,值得所有 AI 開發者與決策者深思。
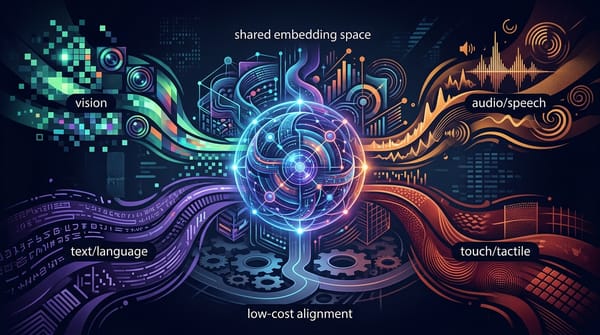
mk-brain 多模態的平台化之路:ImageBind-LLM 如何用「聯合嵌入」降低對齊成本 多模態 AI 的未來,關鍵不在於為每種感官能力都準備昂貴的訓練資料,而是找到更聰明的對齊方法。一篇研究展示,如何利用一個預先對齊好的「聯合嵌入空間」,讓大型語言模型僅需圖文訓練,就能理解音訊、影片、甚至 3D 資訊,這為建立更高效、更具擴充性的 AI 系統指出了明確方向。
mk-brain 不只是預測未來:為什麼預測市場是決策者真正需要的訊號基礎設施 預測市場不只是更精準的民調,它更是將群眾智慧轉化為可計算、可比較的量化訊號的關鍵基礎設施。本文將深入探討,這種「訊號基礎設施」如何為企業風險管理、公共政策,乃至未來的 AI 決策系統,提供前所未有的洞察與自動化潛力。
mk-brain AI 不只加速,更在探索:當 LLM 開始為我們設計演算法 想像一下,AI 不只執行指令,更能自主創造?一篇劃時代研究揭示,大型語言模型(LLM)已能自動探索並發現超越人類專家設計的全新演算法。這不僅是技術突破,更預示著 AI 將從加速工具轉變為制度與系統設計的強大探索者,為我們開啟前所未有的創新可能。
mk-brain 重新理解大型語言模型的幻覺:它不是隨機失誤,而是錯誤框架下的完美推演 AI 幻覺是隨機失誤?還是模型在錯誤框架下,依然完美推演的結果?這篇深入分析將顛覆你對大型語言模型幻覺的認知,並指出解決之道,或許不在修正答案,而在於從源頭阻止錯誤思考框架的啟動。準備好重新審視你對 AI 幻覺的理解了嗎?
mk-brain AI 的信任陷阱:為什麼我們不該預設 Google 的模型必然懂 Google 的服務? AI 模型會犯錯不是新聞,但當 Google 的 Gemini 連自家的服務細節都搞錯時,這揭示了一個更深層的信任問題。真正的風險,不在於模型本身,而在於我們因品牌光環而放下的戒心,錯將本該驗證的資訊當成事實。這篇文章將從一個具體案例,探討 AI 產品的品牌來源如何影響我們的判斷,以及如何建立務實的驗證流程。
mk-brain AI 自我演化的新篇章:當「如何改進」本身成為可編輯的程式碼 近期一篇關於「Hyperagents」的研究,揭示了 AI 發展的下一條關鍵路徑。其核心突破並非單純提升任務效能,而是將「自我改進」的機制本身,從寫死的規則轉變為一個可由 AI 自行編輯、優化的動態程式。這意味著 AI 不僅在學習解決問題,更在學習「如何更有效率地學習」。這種遞迴式的自我加速能力,將系統演化的天花板推向了未知的高度,同時也對我們現有的治理與對
mk-brain 解開長文本的「中間遺忘」魔咒:為何注意力分配比上下文長度更關鍵? 大型語言模型正競相追逐百萬級上下文長度,但這場競賽是否跑錯了方向?本文將深入探討長文本模型普遍存在的「中間遺忘」現象,揭示為何模型在處理長文本時,關鍵資訊常被忽略。我們將介紹一項突破性訓練策略,證明解決方案不在於無止盡的長度擴展,而在於如何更聰明地分配模型注意力,讓 AI 真正「看懂」長文。
mk-brain 校準 AI 的信心:SaySelf 框架如何讓大型語言模型學會自我懷疑 大型語言模型(LLM)的幻覺問題,核心不在於答錯,而是它們對自己的不確定性毫無察覺。SaySelf 框架透過獨特的兩階段訓練,不僅教導模型評估推理品質,更校準其信心表達,這對於打造真正可信賴的 AI 系統至關重要,讓 AI 從「自信滿滿」走向「深思熟慮」。
mk-brain Flash Attention 的隱藏成本:當 BF16 的性能優化遇上數值穩定性挑戰 Flash Attention 作為 AI 性能優化的關鍵,其在 BF16 精度下的數值穩定性卻被 Meta 最新研究點出潛在風險。當追求速度的技術開始影響結果的「正確性」,這份報告不僅揭示了 Flash Attention 的隱藏成本,更提醒所有 AI 工程師:在享受性能紅利的同時,我們該如何重新審視技術選擇,確保系統在高速運轉下依然穩健可靠?
mk-brain 當 LLM 進入 1-bit 時代:運算力的終結,還是記憶體架構的黎明? 微軟最新的 BitNet b1.58 研究顯示,大型語言模型的權重可以被量化到僅有三種狀態,卻能維持與全精度模型相當的效能。這項突破不僅是技術上的里程碑,更可能徹底改變我們對 AI 基礎設施的想像,將設計重心從無盡的算力追逐,轉向對記憶體、頻寬與專用硬體的重新思考。
mk-brain StarCoder2 的啟示:當小模型追上大模型,AI 開發的戰場在哪裡? StarCoder2 的發布不僅是技術進展,更是一個重要的市場訊號。當 15B 參數的開源模型性能足以挑戰 34B 模型時,我們應該思考,AI 開發的競爭關鍵,是否已從追求更大的模型規模,轉向更快的交付速度與更深度的工具鏈整合?