永久記憶的真相:OpenClaw 要可靠,得先把檢索地基打穩
OpenClaw 的永久記憶更像是一套資料工程:文件切塊、向量化、檢索,再把需要的片段餵回模型。本文用工程視角拆解為何記憶會失效,以及本地 embedding 能帶來的穩定性策略。
最近在看 OpenClaw 的「永久記憶」討論,我有一個很實際的感受:大家以為它是功能開關,但它更像是一套資料工程。
你可以先用 memory.md 這種 Markdown 檔撐一陣子;但當你真的把一隻「龍蝦」養到每週都產出筆記、對話、決策紀錄,痛點會出現得很快:
- 上下文越塞越長
- Token 消耗跟著膨脹
- 回答品質卻沒有線性變好(甚至變得不精準)
所謂的永久記憶,最後繞不開的其實是「怎麼把過去的資訊取回來,而且只取回需要的那一小段」。
永久記憶不是把所有東西塞進 Context Window
很多人把永久記憶理解成「長期保存」,然後下次問問題就把全部記憶灌回去。
這在系統層面根本不可行。
Context Window 是有限資源,你愈依賴一次性把資料塞滿,愈容易遇到兩種狀況:
1. 成本上升:每一次對話都在替過去買單
2. 噪音變多:真正需要的訊息被一堆不相關內容稀釋
要做得像「記得住」,靠的是檢索,不是堆疊。
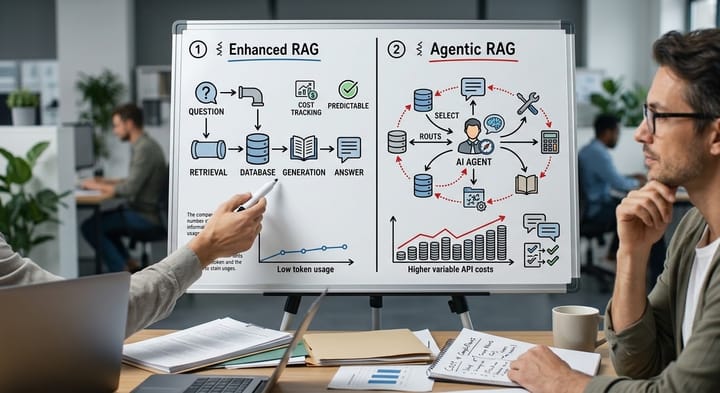
這其實是 RAG 要解的問題
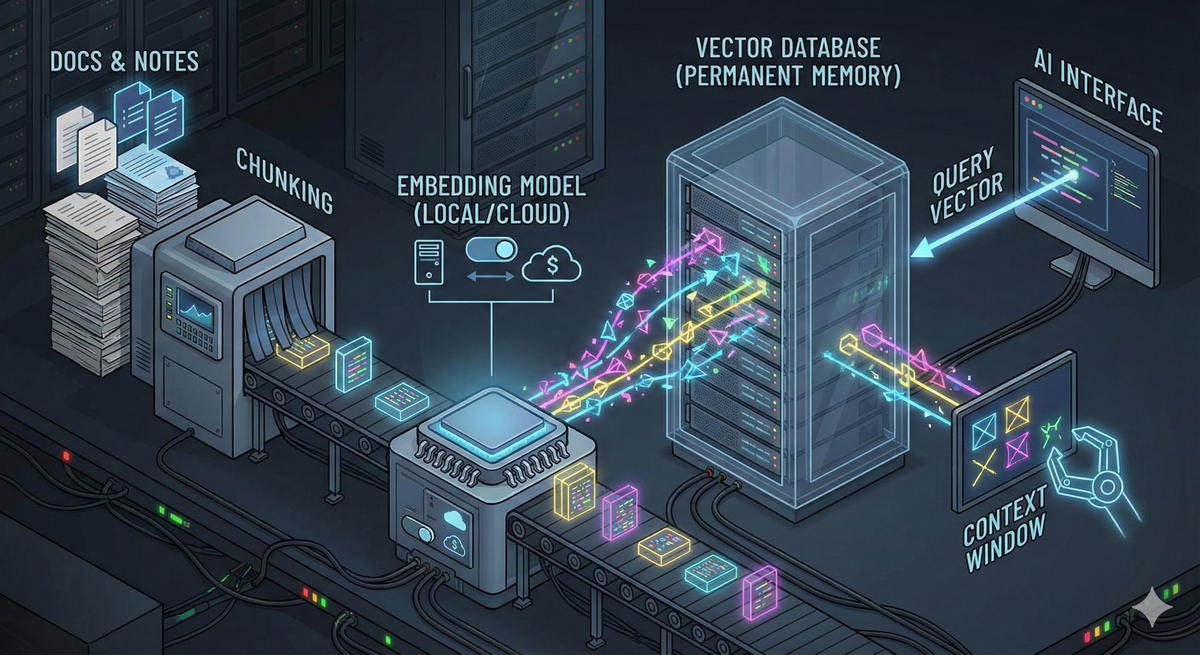
把你過去的文件、對話切成小塊(chunks),轉成向量(embedding),再用「問題的向量」去找最接近的那幾塊內容。接著只把這幾塊餵給模型。
這整套流程聽起來抽象,但它帶來的好處很直接:
- 不用把 50 份 Markdown 全塞進去
- 每次只取回「此刻需要的片段」
- 回答的上下文更乾淨,成本更可控
如果你真的在養一個會持續寫筆記、持續協作的 AI,這幾乎是必修。
你以為是記憶失效,其實常常是 embedding 這一段壞掉
這篇 Threads 裡提到一個場景我很有共鳴:昨天還好好的,隔天突然「失憶」,追查才發現 memory_search 呼叫失敗,原因是 API key 或付費配額問題。
這種狀況在產品上特別陰險,因為它表面看起來像「模型變笨了」,實際上是:
- embedding provider 連不上
- 配額用完
- 金鑰失效
- 付費策略改了
RAG 一旦失效,你就會瞬間退回「只靠當前上下文」的模式。
本地 embedding:不是省錢而已,是可用性策略
很多工具預設用 OpenAI 的 embedding,或者 Gemini 類似服務。
從工程角度看,這本來就會遇到兩個問題:
1. 按量計費:你記憶用得越勤,花費越像背景稅
2. 可用性:你一旦沒金鑰、配額被卡、或服務不穩,記憶功能就會突然斷線
因此,「改成本地 embedding」不只是為了省錢,更像是把一個核心依賴從外部搬回自己掌控的範圍。
如果你要走這條路,務實的做法通常是:
- 保留雲端 provider 當作備援
- 將本地 embedding 設為主要路徑
- 觀察向量模型的大小、速度、與實際查找效果
Threads 文中提到的概念是把 provider 設為 local,讓工具自動下載本地 embedding 模型(例如 embeddinggemma)。這是相對低摩擦的起手式。
讓「永久記憶」變可靠:我會先做的三件事
如果你正在把 OpenClaw 當成長期夥伴使用,我會建議把注意力放在「穩定度」而不是「功能有沒有開」。
1. 先把記憶 pipeline 監控起來:memory_search 成功率、延遲、與失敗原因要看得到
2. 把 provider 當成可替換零件:別讓整套記憶綁死在單一雲端金鑰
3. 用資料量做壓力測試:當筆記變 50 份、100 份時,檢索準確率是否還站得住腳
結語
永久記憶做得好,感覺像在跟一個真的理解你工作脈絡的同事協作;做得不好,就會變成一個每天都要重新暖機的陌生人。
差別往往不在模型參數,而在你有沒有把檢索與 embedding 這條「看不見的地基」鋪穩。
#AI工具 #RAG #Embedding #OpenClaw #工程實作 #知識管理