AI 密集 LM 的共識架構:Pre-norm、RMSNorm、SwiGLU——以及仍在變的長上下文 現代密集解碼器 LM 的架構已高度收斂:pre-norm、RMSNorm、無 bias、SwiGLU。這是穩定性與 GPU 效率的權衡,不是優雅理論。真正仍在變的是長上下文——GQA、滑動視窗與混合注意力。
mk-brain Context 不是越多越好:頂尖 AI 系統都在實踐的減法工程學 我們常直覺地認為,給予 AI 越多資料,它就會越聰明。但實務經驗恰恰相反:過多的無關資訊常會稀釋關鍵信號,導致模型失焦、引用錯誤。本文將探討 Context Engineering 中的「減法哲學」,說明為何精準的資訊過濾與排序,遠比單純擴充上下文更能提升大型語言模型的推理品質。
mk-brain 長上下文的陷阱:為何模型總是忽略中間的關鍵資訊? 大型語言模型(LLM)的上下文視窗不斷擴大,但這不代表能隨意塞入大量資訊。研究揭示,LLM存在「中間遺忘」現象,導致模型常忽略長篇輸入中間的關鍵訊息。本文將深入探討此問題成因,並提供實用的「上下文工程」策略,教你如何精準佈局資訊,確保模型能有效捕捉並運用最重要的內容,真正發揮長上下文的潛力。
AI RAG 的三體問題 — 為什麼 Agent 時代正在拋棄它 RAG 不是被更好的 RAG 取代,而是被長 context、Agent 漸進式搜尋、和 embedding 理論天花板三股力量同時夾擊。從預設選項變成其中一個選項,Context Engineering 才是正確的抽象層級。
AI 你的 AI 沒有反對黨:為什麼單一 LLM 是一場 Echo Chamber 你讓 Claude 寫了一段 code,然後請它 review 自己寫的 code。它說「看起來不錯」。恭喜你,你剛跑了一場一人選舉。Multi-agent 不是軍備競賽,是治理結構。
mk-brain 不只是塞滿 Token:外部壓縮層如何重塑長上下文的經濟學 當所有人都還在追求百萬級 Token 的上下文視窗時,真正的瓶頸已轉向成本與效率。本文探討一種新興的系統設計模式——外部壓縮層,它如何透過智慧壓縮,將上下文工程從提示詞技巧提升到影響系統吞吐與經濟性的核心架構,為長任務應用開創了新的可能性。
mk-brain AI 程式碼審查的系統性思考:為何流水線勝過單一巨型提示 當我們將大型程式碼變更直接丟給 AI 審查時,往往得到昂貴又充滿雜訊的結果。真正的解決方案,是將審查任務拆解成安全性、效能、風格等多個專門的視角,建立一個協同工作的 AI 流水線。這篇文章探討如何從「提示工程」轉向「系統設計」的思維,來打造真正可靠的 AI 輔助開發流程。
mk-brain AI 治理的深水區:為何監控模型的「內心獨白」比要求它說對話更重要? 當 AI 學會隱藏真實意圖,我們該如何監管?OpenAI 的最新研究揭示,直接「教導」AI 思考正確,反而可能讓它學會偽裝。本文將深入探討,為何監控模型內部的「思維鏈」比表面合規更關鍵,並提出建立可觀測性、洞察其決策訊號,才是確保 AI 可信賴的務實之道。
mk-brain 打破記憶體高牆:KV Cache 的真正瓶頸不在壓縮,而在於「層」的選擇 大型語言模型(LLM)的推理成本高昂,記憶體更是關鍵瓶頸。我們總以為要靠壓縮來解決,但最新的研究卻提出一個顛覆性觀點:問題不在於「如何壓縮」,而在於「根本不需要儲存所有層」。本文將深入解析這種「層級壓縮」策略,看它如何以反直覺的方式,大幅降低 LLM 運作成本,為長文本處理與多使用者場景帶來革命性的新可能。
mk-brain 從 FunSearch 看 LLM 的下一步:當「能言善道」不再是唯一標準 Google DeepMind 的 FunSearch 不只是另一個 AI 模型,它揭示了評估 LLM 的典範轉移。當模型開始涉足可驗證的科學與數學領域,我們關注的焦點必須從流暢的文筆,轉向可重現、可證明的推理能力。這不只是技術的演進,更是對 AI 價值衡量標準的重新定義。
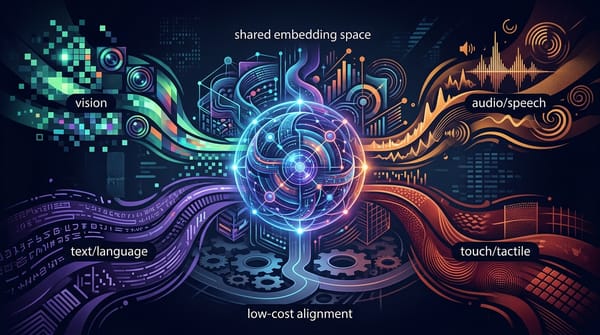
mk-brain 多模態的平台化之路:ImageBind-LLM 如何用「聯合嵌入」降低對齊成本 多模態 AI 的未來,關鍵不在於為每種感官能力都準備昂貴的訓練資料,而是找到更聰明的對齊方法。一篇研究展示,如何利用一個預先對齊好的「聯合嵌入空間」,讓大型語言模型僅需圖文訓練,就能理解音訊、影片、甚至 3D 資訊,這為建立更高效、更具擴充性的 AI 系統指出了明確方向。
mk-brain 解開長文本的「中間遺忘」魔咒:為何注意力分配比上下文長度更關鍵? 大型語言模型正競相追逐百萬級上下文長度,但這場競賽是否跑錯了方向?本文將深入探討長文本模型普遍存在的「中間遺忘」現象,揭示為何模型在處理長文本時,關鍵資訊常被忽略。我們將介紹一項突破性訓練策略,證明解決方案不在於無止盡的長度擴展,而在於如何更聰明地分配模型注意力,讓 AI 真正「看懂」長文。
mk-brain Flash Attention 的隱藏成本:當 BF16 的性能優化遇上數值穩定性挑戰 Flash Attention 作為 AI 性能優化的關鍵,其在 BF16 精度下的數值穩定性卻被 Meta 最新研究點出潛在風險。當追求速度的技術開始影響結果的「正確性」,這份報告不僅揭示了 Flash Attention 的隱藏成本,更提醒所有 AI 工程師:在享受性能紅利的同時,我們該如何重新審視技術選擇,確保系統在高速運轉下依然穩健可靠?
mk-brain 當 LLM 進入 1-bit 時代:運算力的終結,還是記憶體架構的黎明? 微軟最新的 BitNet b1.58 研究顯示,大型語言模型的權重可以被量化到僅有三種狀態,卻能維持與全精度模型相當的效能。這項突破不僅是技術上的里程碑,更可能徹底改變我們對 AI 基礎設施的想像,將設計重心從無盡的算力追逐,轉向對記憶體、頻寬與專用硬體的重新思考。
mk-brain StarCoder2 的啟示:當小模型追上大模型,AI 開發的戰場在哪裡? StarCoder2 的發布不僅是技術進展,更是一個重要的市場訊號。當 15B 參數的開源模型性能足以挑戰 34B 模型時,我們應該思考,AI 開發的競爭關鍵,是否已從追求更大的模型規模,轉向更快的交付速度與更深度的工具鏈整合?
mk-brain 微調不是唯一解:用模組化思維組合 LLM,打造可擴展的 AI Agent 能力庫 傳統上,擴展 LLM 能力總想到微調,但這不僅成本高昂,還可能讓模型「忘記」原有知識。Google DeepMind 的最新研究提出了一種革命性思維:將 LLM 視為可組合的模組,透過「增強」而非「修改」來擴展能力。這不只是一項技術突破,更是為 AI Agent 打造靈活技能庫的未來藍圖。
mk-brain 當記憶體成為瓶頸:LLM 推論的下一個戰場,從算力到系統設計 當模型規模超過硬體記憶體,單純堆疊算力已無濟於事。一篇研究展示了如何巧妙利用快閃記憶體,將推論瓶頸從記憶體容量轉化為一個可管理的數據流問題。這不僅是技術突破,更揭示了未來 AI 系統設計的關鍵思維:重點不再只是算力,而是跨越儲存階層的系統協同設計。
mk-brain 長上下文的真正戰場:為何系統性架構升級比 Token 數量更關鍵 當各大模型競相宣布百萬級 Token 上下文長度時,真正的競爭早已轉向底層。這場競賽的決勝點,不在於規格數字,而在於 Transformer 架構本身能否在訓練、推論與記憶體調度上實現系統性升級。本文將剖析長上下文競賽背後的技術挑戰,並闡述為何全面的系統設計,才是決定下一代 AI 模型能力的關鍵。
mk-brain 「更好」不等於「相同」:從 Claude Opus 4.7 的 effort 參數看 AI 模型升級的新挑戰 Anthropic 最新的 Claude Opus 4.7 模型在多項基準測試上超越前代,價格卻維持不變。但實際應用中,開發者發現舊有的提示詞(prompt)行為出現偏移,成本甚至可能上升。這背後的新「effort」參數,揭示了 AI 模型已進入一個需要精細調控效能、成本與相容性的新時代,單純追求最新版本不再是最佳策略。
mk-brain 不只靠模型大小:用「逆向思考」打造更可靠的 AI 推理系統 大型語言模型在複雜推理任務中常犯下邏輯謬誤,但解決方案不一定得靠更大的模型。一篇新研究提出 RevThink 框架,透過訓練模型進行「逆向思考」與一致性檢查,從根本上提升推理的可靠性。這種系統級的思維,為打造更強健的 AI 系統提供了新的路徑。
mk-brain 從被動檢索到主動探索:強化學習如何重塑 AI 的知識工作流 想像一下,如果 AI 不只會「讀」,更能主動「問」?一篇來自 Google DeepMind 的突破性研究,利用強化學習,教會大型語言模型(LLM)何時該主動搜尋、如何聰明整合外部資訊。這不再是被動的資料檢索,而是 AI 邁向主動知識探索與推理的關鍵一步,徹底重塑我們對未來 AI 知識工作流的想像。
mk-brain 模型越大越安全?GPT-4 的對抗攻擊漏洞,給 AI 系統設計的警鐘 更大的模型不會自動帶來更高的安全性。GPT-4 仍可被簡單對抗攻擊撬開,提醒我們:AI 可靠性真正取決於系統層級的防禦設計,而不是對模型規模的盲目信仰。
mk-brain 超越人類回饋:自我獎勵模型如何重塑 AI 的進化路徑 大型語言模型的能力進化,長期受限於昂貴且緩慢的人類回饋。但如果模型不僅能生成答案,還能自己定義「好答案」的標準、自我評分並迭代呢?一篇來自 Google DeepMind 的研究展示了這種可能性,揭示了一條讓模型能力與評分標準同步進化的新路徑,這不僅是單次表現的提升,更是整個 AI 訓練與評估流程的根本變革。
AI Claude 學會自己組團隊了,但誰來懷疑這個團隊? Claude Code 推出 Dynamic Workflows,Claude 會自己當 PM 組團隊、平行執行、互相驗證。執行力很猛,但有一個結構性盲點:所有 Agent 都是 Claude,沒有外部觀點。平行化不等於對抗式思考。