我怎麼用 7 個 AI 模型協作,成本砍 70%——完整路由設定公開
從「全部丟 GPT」演化成 7 個模型協作的架構。路由邏輯、成本結構、踩過的坑,附可直接跑的 Python router。

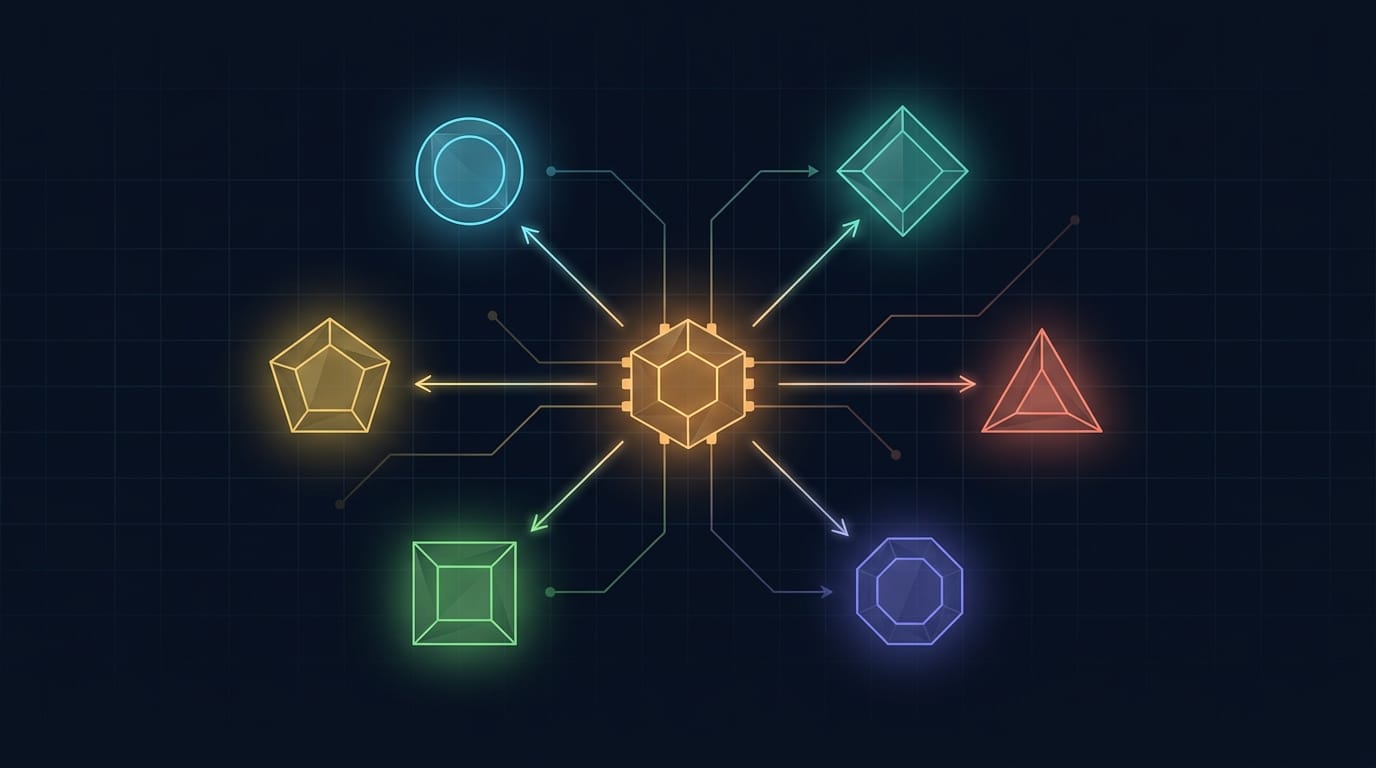
大多數人用 AI 的方式是:打開 ChatGPT,什麼都丟進去。進階一點的人會挑模型——「這個任務用 Claude 比較好」「那個用 Gemini」。但很少人認真想過:能不能建一套系統,讓任務自動流向最適合的模型?
我花了半年時間,從「全部丟 GPT」演化成 7 個模型協作的架構。這篇文章把完整設定攤開來,包括路由邏輯、成本結構、踩過的坑。可以直接抄。
先講結論:為什麼不是一個模型打天下
一個模型打天下有三個問題:
成本失控。 簡單的格式轉換、摘要、制式回覆佔了八成請求,全丟旗艦模型等於用賓士載垃圾。
延遲不均。 旗艦模型推理慢,簡單任務等 3-5 秒是不必要的。本地模型 200ms 就能回。
單點故障。 API 掛了就全掛。多模型意味著 fallback 路徑。
七位一體:每個模型為什麼在這裡
不是為了湊數。每個模型進來都是因為有一個具體缺口:
角色 模型 為什麼是它
─────────────────────────────────────────────────────
Architect Claude Opus 推理天花板,不可逆決策
Engineer Codex sandbox 可跑測試驗證,
code review cost/quality 甜蜜點
Analyst Gemini 100 萬 token context,
整個 repo 丟進去分析
Local Brain Qwen 3.6 35B (A3B) 自家 DGX Spark 跑,
批次 / 隱私 / 投票,零 API 費
Writer Gemma4 31B 本地跑,中文寫作品質高,
文章生成 / 改寫
Scout-1 Perplexity Max 即時搜尋 + 自動帶引用
Scout-2 SuperGrok X / 社群即時情報
為什麼 Scout 要兩個?
Perplexity 擅長結構化 research(學術、技術文件、帶引用),SuperGrok 擅長即時社群(X 趨勢、輿論風向)。兩者搜的東西不重疊,不是冗餘。
為什麼本地模型要兩個?
Qwen 3.6 是 MoE 架構(35B 參數但只啟動 3B),推理極快、記憶體佔用低,適合大量批次和投票。Gemma4 31B 是 dense 架構,寫作品質更好但推理較慢,只在需要中文寫作時才叫它。不是同時跑。
路由決策樹:什麼任務派給誰
這是我實際在用的判斷邏輯:
收到任務
│
├─ 單檔、≤3 行、明確可逆?
│ └─ YES → fast-path:Claude 直接做,不路由
│
├─ 有時效性需求?(今天的新聞、現在的趨勢)
│ └─ YES → Scout-1 或 Scout-2
│ (學術/技術 → Perplexity,社群/X → Grok)
│
├─ 碰到不認識的專有名詞?
│ └─ YES → 先查個人知識庫(4200+ 書籤語意搜尋)
│ 查到 → 直接用,不花 API
│ 查不到 → 再派 Scout
│
├─ 寫 code / refactor?
│ └─ YES → Codex(有 sandbox,能跑測試驗證)
│
├─ 程式碼分析 / 多方案比較?
│ └─ YES → Gemini(大 context 窗口吃整包)
│
├─ 簡單任務 / 隱私資料 / 批次處理 / Council 投票?
│ └─ YES → Qwen 本地跑
│
└─ 架構設計 / 不可逆決策 / 最終裁判?
└─ YES → Claude Opus
四個預設模式
不是每次都跑完整棵樹。我把常見情境打包成四個 preset:
| Preset | 條件 | 誰參與 |
|---|---|---|
| fast-path | 單檔 ≤3 行、明確、可逆 | Claude 自己做 |
| solo+review | 一般實作 | Claude 做 + Codex review |
| council-lite | 跨系統、中風險 | Claude + Codex + 1 analyst |
| full-council | 不可逆、治理、戰略 | 全員投票 |
90% 的時間在 fast-path 和 solo+review。full-council 是 escalation,不是常態。
實際怎麼呼叫:CLI 指令
每個模型都透過 CLI 操作,統一用 file I/O 傳遞(寫 briefing 檔、讀 answer 檔):
# Codex — sandbox 內執行,可寫檔但隔離
codex exec --sandbox workspace-write \
--skip-git-repo-check < briefing.md > answer.md
# Gemini — pipe 模式
gemini -p "Execute the briefing on stdin." \
< briefing.md > answer.md
# Grok — 關掉 web search 避免干擾
grok -p "$(cat briefing.md)" \
--disable-web-search 2>/dev/null > answer.md
# Qwen(本地 DGX Spark)
ollama run qwen3.6 < briefing.md > answer.md
# Gemma4(本地 MBP 或 DGX)
ollama run gemma4:31b < briefing.md > answer.md
Briefing 檔格式固定四段:TASK / CONTEXT(貼真 code)/ CONSTRAINTS / VERIFY。不給完整 context 的 briefing 等於叫人矇眼做事。
成本結構:真實數字
以一週工作日估算:
任務分佈 模型 單位成本 週成本估算
────────────────────────────────────────────────────────────
60% 日常/批次/投票 Qwen 本地 $0 $0
15% Code review Codex ~$0.003/req ~$2
10% 分析/比較 Gemini ~$0.005/req ~$2
10% Scout research Perplexity/ ~$0.01/req ~$3
Grok
5% 架構/裁判 Claude Opus ~$0.05/req ~$5
────────────────────────────────────────────────────────────
合計 ~$12/週
如果全部用 Claude Opus:同樣的量大約 $35-40/週。差距是 3 倍。
如果你沒有 DGX / 本地 GPU,把 Qwen 換成 Gemini Flash 或 GPT-4o-mini,成本會從 $0 變成 $1-2/週,整體還是比全用旗艦便宜很多。
踩過的坑(省你踩一次)
坑 1:模型切換後 payload 不相容
Ollama 換模型版本後,max_tokens 變成 max_completion_tokens、response_format 格式變了。結果 scoring pipeline 靜默失敗,跑了兩天才發現分數全是 0。
教訓:模型更換必須與 bug 修復分開做。同時改會互相掩蓋失敗。換模型三步驟:① 檢查 payload schema ② 確認 VRAM ③ 跑測試比對結果。
坑 2:本地模型 context 太長吃光記憶體
DGX Spark 128GB unified memory。Ollama 對 ≥48GB 設備自動拉 context 到 256K,結果 swap thrashing,第一次 LLM call 卡了 28 分鐘。
教訓:一定要手動設 num_ctx=8192。不要信任預設值。
坑 3:把 code review 也交給最強模型
一開始覺得 review 需要最強的推理。後來發現 Codex 的 review 品質不差,而且它有 sandbox 可以真的跑程式驗證,Claude 反而只能看。
教訓:最強 ≠ 最適合。Codex 在 code review 這個特定任務上,因為工具能力(sandbox)反而比 Claude 更合適。
坑 4:三家共識不等於正確答案
Council 投票時,Codex / Gemini / Grok 三方都說「方案 A 好」。後來 Perplexity 帶著 GitHub issues 和 benchmark 數據說「方案 A 在你的硬體上會失敗」,結果是對的。
教訓:一個帶完整 evidence 的反對意見,可以推翻三方共識。投票制度要保護 dissent,不能靠多數決壓過去。
從兩層開始就好
看到這裡可能覺得太複雜。其實不用一開始就搞七個模型。我的建議:
第一步:把你現在的任務分成「需要推理」和「不需要推理」兩堆。
第二步:不需要推理的,換一個便宜模型(Gemini Flash / GPT-4o-mini / 本地 Ollama)。光這步就能砍一半成本。
第三步:觀察哪些任務便宜模型做不好。那些就是你第三層的候選。
架構是長出來的,不是第一天設計出來的。但前提是你要開始分流。
附錄:最小可執行路由器(單檔,15 分鐘跑通)
光講概念不夠,這裡附一個可以直接跑的 Python router。單檔、無外部依賴、120 行。
"""router.py — 最小多模型路由器"""
import shutil, subprocess, sys, time
# ── 路由規則:keyword → model ──
RULES = [
("local", ["翻譯","摘要","格式化","列出","整理","簡單","分類"]),
("codex", ["寫 code","寫程式","refactor","debug","bug","code review",
"review","decorator","api","endpoint"]),
("gemini", ["分析","比較","整個 repo","大量","讀完這份","對比"]),
("scout", ["最近","趨勢","新聞","現在","即時","今天"]),
("opus", ["架構","不可逆","戰略","決策","migrate","治理"]),
]
# ── 模型指令 ──
MODELS = {
"local": {"cmd": ["ollama","run","qwen3.6"], "stdin": True},
"codex": {"cmd": ["codex","exec","--sandbox","workspace-write",
"--skip-git-repo-check"], "stdin": False},
"gemini": {"cmd": ["gemini","-p"], "stdin": False},
"scout": {"cmd": ["gemini","-p"], "stdin": False},
"opus": {"cmd": ["claude","-p"], "stdin": False},
}
# ── Fallback 鏈 ──
FALLBACK = {
"codex": ["gemini","opus"], "gemini": ["opus","local"],
"scout": ["gemini","local"], "opus": ["gemini"],
"local": ["gemini"],
}
def classify(task):
for key, keywords in RULES:
if any(kw in task.lower() for kw in keywords):
return key
return "local"
def resolve(key):
if shutil.which(MODELS[key]["cmd"][0]):
return key
for fb in FALLBACK.get(key, []):
if shutil.which(MODELS[fb]["cmd"][0]):
print(f" fallback → {fb}", file=sys.stderr)
return fb
return "local"
def call(key, prompt):
cfg = MODELS[key]
cmd = cfg["cmd"] if cfg["stdin"] else cfg["cmd"] + [prompt]
inp = prompt if cfg["stdin"] else None
t = time.monotonic()
r = subprocess.run(cmd, capture_output=True, text=True,
timeout=120, input=inp)
return r.stdout.strip(), time.monotonic() - t
if __name__ == "__main__":
task = " ".join(sys.argv[1:]) or input("Task: ")
route = classify(task)
final = resolve(route)
print(f"[{route} → {final}]", file=sys.stderr)
output, elapsed = call(final, task)
print(output)
print(f"[{elapsed:.1f}s]", file=sys.stderr)
跑法
# 安裝(你可能已經有了)
# brew install ollama # 或 https://ollama.com
# ollama pull qwen3.6
# 基本用法
python router.py "翻譯成英文:今天天氣很好"
# → [local → local] → Qwen 本地處理,0 成本
python router.py "幫我寫一個 rate limiter"
# → [codex → codex] → Codex sandbox 執行
python router.py "分析這兩個方案的優缺點"
# → [gemini → gemini] → Gemini 大 context 分析
python router.py "最近 AI agent 有什麼新方向"
# → [scout → gemini] → Scout 不可用時 fallback 到 Gemini
# Dry run(只看路由不執行)
python router.py "這個架構怎麼設計" --dry-run
關鍵設計
為什麼用 keyword 而不是 LLM 分類? 因為路由本身不該吃 token。keyword 匹配 0 成本、<1ms。等你的任務量大到 keyword 不夠用了,再換成小模型分類也不遲。
Fallback 鏈怎麼設計? 每個模型有一條降級路徑。Codex 掛了走 Gemini,Gemini 掛了走 Opus,最後都能 fallback 到本地。生產環境不能有「某個 API 掛了就整個停」的情況。
為什麼不做 retry? 簡單。retry 加上指數退避、最大次數、circuit breaker,會把這 120 行膨脹到 400 行。先跑通,再加防禦。
踩坑補充:觸發條件和解法
四家評審說踩坑細節不夠深,這裡補完:
坑 1 詳解:Payload 不相容
觸發條件:Ollama 從 qwen2.5 升級到 qwen3 時發生。max_tokens 參數被重新命名為 max_completion_tokens,response_format: {"type": "json"} 在新版需要改成 format: "json"。
症狀:不會報錯。模型照樣回覆,但 JSON 輸出格式壞了,下游 parsing 全拿到空值。我的 scoring pipeline 靜默跑了兩天才發現分數全是 0。
解法:模型更換三步驟(鐵律)——① 先在測試環境比對 API schema diff ② 確認 VRAM 夠 ③ 跑 benchmark 比對輸出。三步分開做,不與 bug fix 混在同一個 commit。
坑 2 詳解:Context 吃光記憶體
觸發條件:DGX Spark 128GB unified memory。Ollama 偵測到 ≥48GB RAM 的設備,會自動把 context window 拉到 256K token。一個 8K 的 prompt 就足以觸發——因為 KV cache 是跟著 context window 配置的,不是跟著實際 prompt 長度。
症狀:不是 OOM crash。Linux kernel 開始 swap,表面上 Ollama 還活著,但第一次推論卡了 28 分鐘。free -h 看到 available < 5GB,ollama ps 看到 CONTEXT 欄位顯示 256K。
解法:API 呼叫一定帶 "options": {"num_ctx": 8192}。不要信任 Ollama 的預設值。如果用 native /api/chat(推薦),直接塞在 options 裡;如果走 OpenAI-compatible endpoint,要注意 num_ctx 不是 OpenAI 標準參數,Ollama 會靜默忽略。
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。