AI 當 AI Skill 不再是工程師專利:一個讓全團隊安全貢獻自動化的設計 讓非工程師也能安全貢獻可執行的 AI 自動化工具——用一個輕量的權限閘道把資料外洩風險關起來,同時不殺死人人都能貢獻的彈性。
AI Claude 學會自己組團隊了,但誰來懷疑這個團隊? Claude Code 推出 Dynamic Workflows,Claude 會自己當 PM 組團隊、平行執行、互相驗證。執行力很猛,但有一個結構性盲點:所有 Agent 都是 Claude,沒有外部觀點。平行化不等於對抗式思考。
mk-brain RAG 的下一步:別再堆疊檢索器,讓模型自己決定怎麼搜 RAG 系統越堆越複雜,卻發現效率不增反降?一篇名為 A-RAG 的最新研究,為我們指出了一條新路:與其不斷疊加檢索模組,不如將決策權交還給大型語言模型(LLM),讓它像一位經驗豐富的研究員,自主判斷何時、如何、以何種粒度進行資訊檢索。這不僅是技術上的突破,更預示著 AI 系統設計思維的根本性轉變,準備好一窺 RAG 的未來了嗎?
mk-brain AI Agent 的下一步:為何記憶體與系統設計,比純算力更關鍵? 當我們追求更強大的 AI Agent 時,真正的瓶頸已悄悄轉移。這篇文章將帶你深入探討,為何記憶體頻寬與系統架構,而非單純的算力堆疊,才是決定未來 AI Agent 效能與應用廣度的關鍵。一篇最新研究揭示,只有透過硬體與模型的協同設計,我們才能真正突破當前困境,讓 Agent 應用在現實世界中發光發熱。
mk-brain 強化學習的下一步:當模型學會「自我檢討」,而不只是追求分數 傳統強化學習仰賴單一分數回饋,模型往往只學會碰運氣。一篇新研究提出,讓模型產生語言化的自我反思,並將這些反思「蒸餾」回自身策略,才能真正從錯誤中學習,解決棘手的信用分配問題,為更穩健的 AI 代理人開闢了新路徑。
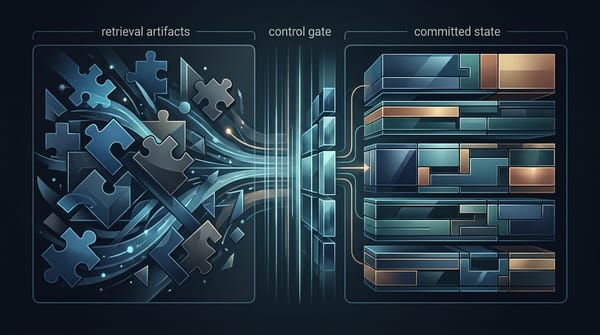
mk-brain AI Agent 的記憶難題:為何區分「參考」與「承諾」比無限擴充上下文更重要 當我們追求更強大的 AI Agent 時,常誤以為記憶問題的解法是塞入更多上下文。但真正的關鍵在於記憶的「控制」,而非容量。本文探討一種新思路:如何讓 Agent 學會區分哪些資訊只是參考,哪些是會改變其核心狀態的「承諾」,從而避免在長期任務中迷失方向。
mk-brain Agent 效能再思考:為何成功率不是唯一指標,成本預算才是? 當前的 AI Agent 評估過度專注於任務成功率,卻忽略了延遲、Token 消耗等關鍵成本。本文從一篇近期的研究出發,探討為何我們需要一個包含成本預算的多維度效率框架,並分析如何在記憶、工具學習與規劃等層面,打造真正能在現實世界中部署的「經濟型」智能。
mk-brain 不只堆疊更多層:當模型架構本身成為可學習的設計空間 深度學習的未來,不再只是堆疊更多層或餵養更多資料。一篇名為《Deep Delta Learning》的開創性研究,正引領我們重新思考模型架構的本質:當殘差連接不再是固定的「加法」,而是可學習的「動態變換」,資訊流動的路徑本身,也能成為模型學習的設計空間。這不僅提升了模型效能,更預示著一個模型結構能自我演化的新時代。
mk-brain 別再逐字抄寫系統提示詞了:從 Claude 內部文件,看見模型行為的真實設計藍圖 最近一份號稱 Claude Opus 4.7 的系統提示詞文件在網路上流傳,但深究其內容,你會發現真正的價值不在於那些可以複製貼上的指令,而在於它揭示了 Anthropic 如何透過結構化的角色、工具與約束,來塑造 AI 的核心行為模式。這份文件就像一份設計藍圖,教我們如何思考,而非如何抄寫,為我們提供了理解頂尖模型運作邏輯的獨特視角。
mk-brain 從單人助理到團隊協作:AI Agent 的下一個系統級挑戰 當 AI Agent 從個人助理走向企業團隊,真正的挑戰並非同時處理多個對話,而是系統如何應對權限衝突、角色優先級與隱私邊界。這不僅是模型能力的延伸,更是對系統設計、責任歸屬與信任基礎的根本拷問。
mk-brain 觀測性陷阱:當 AI Agent 的 Trace 看起來正常,但結果卻是錯的 AI Agent 的執行紀錄(Trace)讓我們看見它做了什麼,卻沒告訴我們它做得對不對。當我們過度依賴這些表面訊號,很容易將「觀測性」誤判為「可靠性」。本文將探討如何建立可判定的診斷機制,真正量化 Agent 的行為正確性,避免它們在看似正常的運作下悄悄失敗。
mk-brain MCP 原型的詛咒:為何成功的 PoC 反而走向技術債的懸崖? 許多團隊在開發多輪對話協定(MCP)系統時,常因追求快速驗證而忽略初期架構的嚴謹性。本文將深入探討,為何這種「先求有再求好」的思維,會讓看似成功的原型在邁向生產環境時,撞上名為「安全之崖」的絕壁,最終導致難以挽回的技術債。這是一篇關於如何避免 MCP 專案從成功走向失敗的警世文。
mk-brain AI 治理的真正瓶頸:從人工審核到自動化驗證 當 AI 應用在企業內遍地開花,您是否正為日漸龐大的人工審核成本所苦?本文將深入剖析,如何將傳統的 AI 治理模式,從耗時費力的人力審查,轉型為高效、可規模化的自動化驗證管線。探索將評估標準結構化為機器可執行邏輯的關鍵步驟,徹底解放您的團隊,實現永續的 AI 規模化治理。
mk-brain AI Agent 的「無伺服器」時刻:當 AWS Bedrock 將開發重心從編碼轉向系統設計 AWS Bedrock AgentCore 的「Managed Agent Harness」預覽功能,讓 AI Agent 開發從繁瑣的編碼轉向簡潔的宣告式配置。這不僅大幅降低了開發門檻,更預示著產業重心將從流程控制,轉移至更深層次的系統設計與治理。當 Agent 核心循環成為託管服務,真正的競爭力將來自於我們如何設計穩健工具、規劃有效知識庫,並建立完善的監
mk-brain AI Agent 上線前的最後一哩路:為何我們需要從「結果驗收」走向「軌跡評估」? AI Agent 在生產環境中表現不穩定,傳統測試方法束手無策?本文深入解析為何我們必須將品質保證的重心,從單純的「結果驗收」轉向對 Agent 完整「執行軌跡」的嚴格評估。這不僅是為了提升可控性與可追溯性,更是打造可信賴、可診斷 AI 系統的關鍵策略,助您掌握 Agent 上線前的最後一哩路。
mk-brain 多代理系統的下一步:從預設流程圖到動態遞迴分工 目前的多代理系統,常依賴我們預先畫好的流程圖來協作。但如果系統能根據任務的複雜度,動態生成解決問題的團隊呢?一個名為 ReDel 的新框架,正在探索這種「遞迴分工」的可能性。這或許才是讓 AI Agent 真正處理複雜、開放式問題的關鍵一步,讓它們從單純的執行者,進化為能夠自主規劃與組織的協作者。
mk-brain 不只是模型:Claude Code 的 Harness 如何打造自律的 AI 開發閉環 AI 寫程式的競賽已進入下半場。當模型能力趨於一致,真正的差異在於如何將環境、工具與任務脈絡整合成可持續運轉的開發循環。本文從 Anthropic 的 Claude Code Harness 機制切入,探討 AI 如何從指令執行者,進化為能自主測試、修正、迭代的開發夥伴。
mk-brain AI 推理能力的真正瓶頸:昂貴的「過程監督」與自動化的解方 訓練 AI 進行複雜推理,最昂貴的不是模型本身,而是步步為營的「過程監督」資料。一篇新研究展示了如何用演算法自我生成監督訊號,這不僅大幅降低成本,更可能改寫 AI 能力擴張的遊戲規則。
mk-brain 從 few-shot 範例到高層次推理:AI 思考模式的下一次演進 我們習慣用 few-shot 範例引導大型語言模型,但這就像只給學生看例題,卻不教解題方法。一篇新研究提出,讓模型學習抽象的「推理模式」,而非記憶特定範例,能讓小模型在複雜任務上超越 GPT-4o,這可能預示著提示工程與模型推理能力的下一個典範轉移。
mk-brain AI 編碼的下一個戰場:當大型語言模型開始讀懂編譯器 IR 當我們還在驚嘆於 AI 程式碼生成時,真正的革命已悄悄深入系統底層。Meta 的研究展示,LLM 不僅能寫上層應用,更能學習編譯器的中間語言(IR),將耗時的效能調優搜索,轉化為高效率的預測。這不只是工具的演進,更是軟體工程典範的轉移。
mk-brain 算力不是越多越好:Mixture-of-Depths 如何教我們聰明地「跳過」計算 傳統上,我們追求更強大的 AI 模型,總習慣無止盡地堆疊算力。然而,Google DeepMind 的最新研究《Mixture-of-Depths》提出了一種更聰明的途徑:讓模型動態決定哪些計算值得投入,哪些可以直接跳過。這種「選擇性計算」的思維,不僅能將推理速度提升超過 50%,更為下一代 AI 的效率與成本效益指出了明確方向,預示著算力運用模式的典範轉移
mk-brain 超越草稿模型:Medusa 如何從系統架構層面重塑 LLM 推理效率 當我們追求大型語言模型(LLM)的極致推理速度時,多數人會直覺地想到「推測解碼」(Speculative Decoding)。然而,Medusa 框架卻提出了顛覆性的觀點:真正的瓶頸並非需要一個更快的草稿模型,而是如何從根本的系統架構上,打破 LLM 自回歸的序列限制。本文將深入探討 Medusa 如何透過巧妙的多個解碼頭設計,實現並行預測與驗證,將推理延遲
mk-brain AI Agent 的信任難題:從罕病診斷看見「可追溯推理」的價值 AI Agent 的能力日益強大,但當它涉足醫療、金融等高風險領域時,光有「聰明」還不夠,更需要「信任」。本文將深入探討一篇針對罕見疾病診斷的多代理系統研究,看它如何透過留下清晰、可供專家審計的推理軌跡,將AI從難以捉摸的「黑箱」轉變為可靠的「數位助理」。了解「可追溯性」如何成為建立人機協作信任,並讓AI真正落地關鍵場景的入場券。
mk-brain 小模型逆襲:高品質合成數據如何讓 7B 模型在工具調用上超越 GPT-4? 我們常以為模型越大越好,但一篇新研究顯示,透過高品質、可驗證的合成數據,7B 小模型在特定工具調用任務上竟能超越 GPT-4。這不僅挑戰了「大就是好」的迷思,也為 AI 應用開發者指出一條更高效、更經濟的路徑,證明了在明確的任務邊界下,數據品質的護城河遠比模型參數量更深。
mk-brain 長上下文的幻覺:我們真的需要百萬 token 的記憶嗎? 業界對超長上下文(Long Context)的競逐日益激烈,但我們可能問錯了問題。一篇新的研究顯示,大型模型在長上下文中的優異表現,並非來自於對資訊的深度「理解」或「記憶」,而更像是一種高效的「即時工具檢索」。這意味著,盲目擴大 context window 未必是建構強大 AI 系統的最佳路徑;更聰明的任務拆解、外部記憶體整合與工具使用,或許才是更務實且高