AI Agent 的記憶難題:為何區分「參考」與「承諾」比無限擴充上下文更重要
當我們追求更強大的 AI Agent 時,常誤以為記憶問題的解法是塞入更多上下文。但真正的關鍵在於記憶的「控制」,而非容量。本文探討一種新思路:如何讓 Agent 學會區分哪些資訊只是參考,哪些是會改變其核心狀態的「承諾」,從而避免在長期任務中迷失方向。

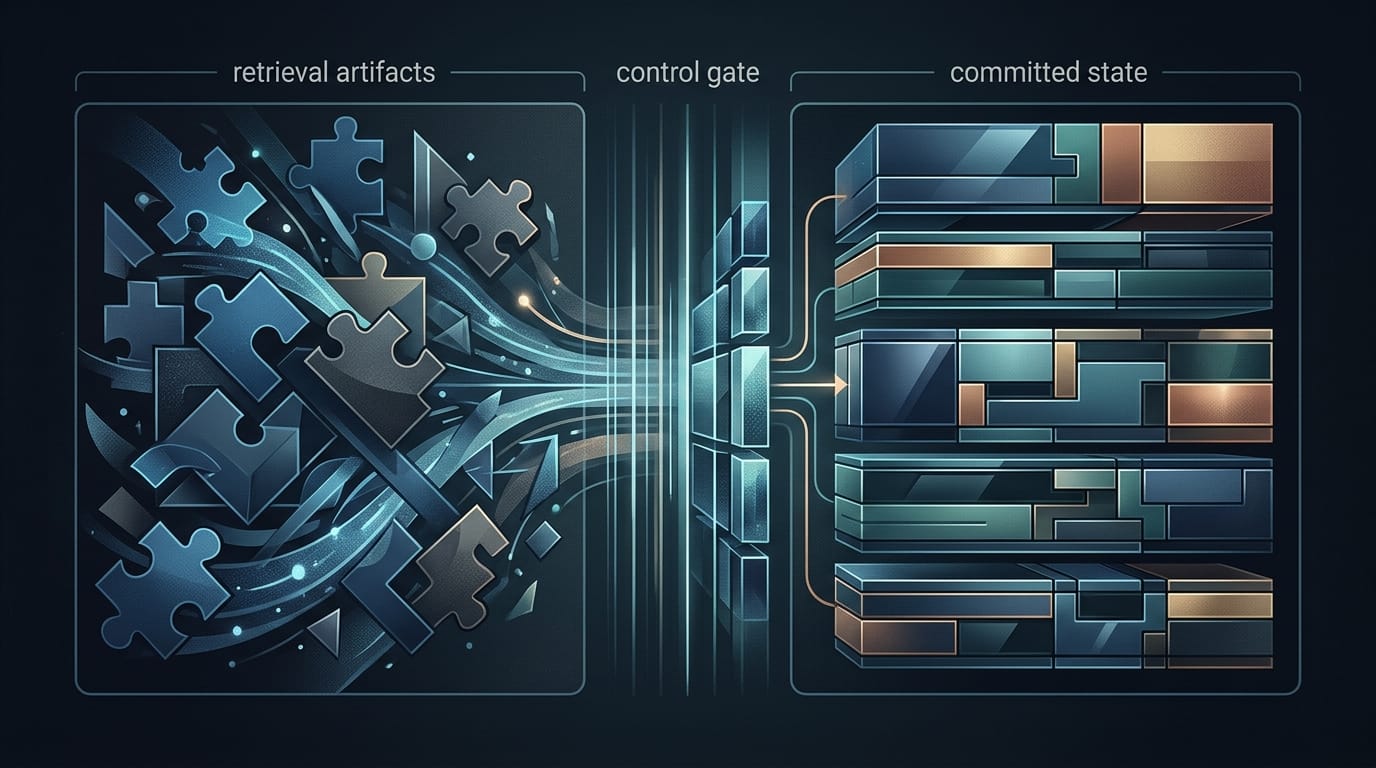
在建構 AI Agent 的過程中,我們常誤以為只要無限擴大模型的記憶窗口,就能解決其在長期任務中的一致性與可靠性問題。然而,這種「上下文軍備競賽」的思維,正將我們引向死胡同。真正的關鍵,不在於讓 Agent 記住「所有事」,而是建立一套精準的記憶控制機制。這套機制能讓 Agent 明確區分哪些資訊僅是暫時的「參考資料」,哪些則是會永久改變其核心任務狀態的「狀態承諾」。這不僅是技術路線的選擇,更直接決定了我們能否打造出真正自主且可靠的 AI 系統。
為什麼更大的上下文窗口,反而會讓 Agent「迷失自我」?
近年來,大型語言模型的上下文窗口(Context Window)經歷了爆炸性成長,從早期數千 token,迅速擴展到如 Google Gemini 1.5 Pro 宣稱的 100 萬 token,甚至更高。直覺上,更大的記憶容量似乎能讓 Agent 在更長的時間尺度上保持對話連貫性與任務目標的記憶。然而,實務經驗與學術研究都顯示,這條路充滿了挑戰。
上下文過長會帶來哪些問題?
首先是「大海撈針」的難題。當上下文變得極度龐大時,模型很難精準地從數十萬 token 的資訊噪音中,找到最關鍵的那一小段。史丹佛大學的一項研究就明確指出了「Lost in the Middle」現象:模型對於上下文開頭和結尾的資訊記憶較好,但中間部分的資訊很容易被忽略或誤解。對一個需要長時間運作的 Agent 而言,這意味著它可能會忘記幾個小時前用戶下達的關鍵指令。
其次,是更隱晦的「語義漂移」(Semantic Drift)。在一個冗長的對話歷史中,充滿了各種假設、提問、修正與閒聊。如果 Agent 將所有這些對話都視為同等重要的「記憶」,它的核心目標或「世界觀」就可能被這些暫時性的、甚至互相矛盾的資訊所污染。
舉例來說,在一次專案討論中,團隊可能腦力激盪了五種不同的方案,但最終只決定採納其中一種。如果 Agent 無法區分「被討論過的方案」(參考)與「最終決議」(承諾),它很可能會在後續的任務規劃中,錯誤地引用已被否決的方案,導致行為失控,甚至偏離核心目標。
AI Agent 能從生物記憶中學到什麼?
近期一篇發表於 arXiv 的論文《AI Agents Need Memory Control Over More Context》(2026)提出了一個有趣的解決思路,其核心概念是建立一個受生物認知啟發的「Agent 認知壓縮器」(Agent Cognitive Compressor, ACC)。這個框架的重點,不再是傳統的對話重播(Replay)或單純的資訊檢索(Retrieval),而是引入了「有界的內部狀態更新」(Bounded Internal State Update)機制。
這個概念聽起來抽象,但我們可以從人類的記憶模式來類比。我們的大腦並不會像錄影機一樣儲存所有感官輸入。我們的記憶是有選擇性的、經過高度壓縮和整合的。日常對話的細節很快會被遺忘(可回收的參考),但一個重要的承諾、一個新學到的技能、或是一個改變我們信念的事件,則會被整合、寫入我們更深層的認知狀態中,從而永久性地改變我們未來的決策模式(狀態承諾)。
真正的智慧,不在於記住一切,而在於知道該忘記什麼,以及該把什麼刻進骨子裡。
ACC 框架正是試圖在 Agent 內部模擬這個過程。它不把對話歷史當成一個巨大的、扁平的資料庫來檢索,而是將其視為一個持續的輸入流,用來更新 Agent 的一個小而精悍的「內部狀態」。
如何劃定「參考」與「承諾」的界線?
那麼在實務上,Agent 該如何區分這兩種性質截然不同的資訊呢?這需要我們在系統設計層面就做出明確的劃分。一個可行的做法是建立一個分層的記憶系統,將資訊依其重要性與持久性進行分類:
分層記憶系統:短期工作記憶與長期狀態記憶
短期工作記憶(Short-term / Working Memory):這層記憶類似傳統的上下文窗口,用於處理即時的對話與任務。它儲存的是大量、未經處理的原始資訊,可視為「可回收的參考」。例如,用戶當前的問題、檢索到的網頁片段、程式碼的草稿等。這層記憶是易變的,可以被隨時刷新,不對 Agent 的核心狀態造成永久影響。
長期狀態記憶(Long-term / State Memory):這是一個高度結構化、經過嚴格驗證才能寫入的核心記憶層。它儲存的是「狀態承諾」。只有當某些資訊被明確標記為「決策」、「指令」或「事實」時,才能觸發更新機制,將其壓縮並寫入此層。例如,「用戶已確認,專案最終交付日期為 2026 年 8 月 15 日。」這個資訊一旦寫入,就成為 Agent 後續所有規劃的絕對基礎,其權重遠高於任何短期記憶中的討論過程。
這種分層架構,讓 Agent 的行為變得更加穩定與可預測。它不會因為對話中的一句玩笑話或一個被否決的提議,就輕易改變自己的核心任務目標。這也為複雜的多 Agent 協作提供了基礎。Agent 之間交換的,不應該是冗長的對話歷史,而應該是經過驗證的「狀態承諾」,確保整個系統的目標一致性。
從 RAG(Retrieval-Augmented Generation)到更複雜的 Agent 框架如 Generative Agents,我們看到 AI 系統與外部知識互動的能力越來越強。但如果沒有精細的記憶控制,這些能力反而可能成為系統不穩定性的來源。未來,真正強大的 Agent,或許不是擁有最大記憶體的那一個,而是最懂得如何「慎思明辨」,區分輕重緩急,並做出堅定「承諾」的那一個。這條路需要我們從追求「更多上下文」的蠻力思維,轉向設計「更智慧的記憶結構」的精細化工程。
延伸閱讀
- Bousetouane, F. (2026). AI Agents Need Memory Control Over More Context. arXiv:2601.11653 [q-bio.NC].
- Liu, N. F., et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172 [cs.CL].
- Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 [cs.CL].
- Park, J. S., et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442 [cs.HC].
我是江中喬,專注於 AI Agent Architecture、Memory Governance 與 Cognitive Diversity,持續研究如何打造能夠長期協作、可信任且可治理的 AI 系統。