我做了三個月的「七位一體」,跟 Perplexity Max 的「模型委員會」拓樸一模一樣——除了一個關鍵差別
今天看到 Perplexity Max 推出「模型委員會」(Model Council),它的拓樸跟我自己跑了三個月的「七位一體」幾乎一模一樣。但繼續往下讀,我意識到這件事的意義不是「我被抄了」或「業界終於追上了」——而是一個更有意思的問題:長得一樣的兩個東西,本質可以差非常多。

當你發現業界 SaaS 巨頭做的東西跟你一樣,這件事該開心還是該緊張?答案是兩個都不是。
一個小發現
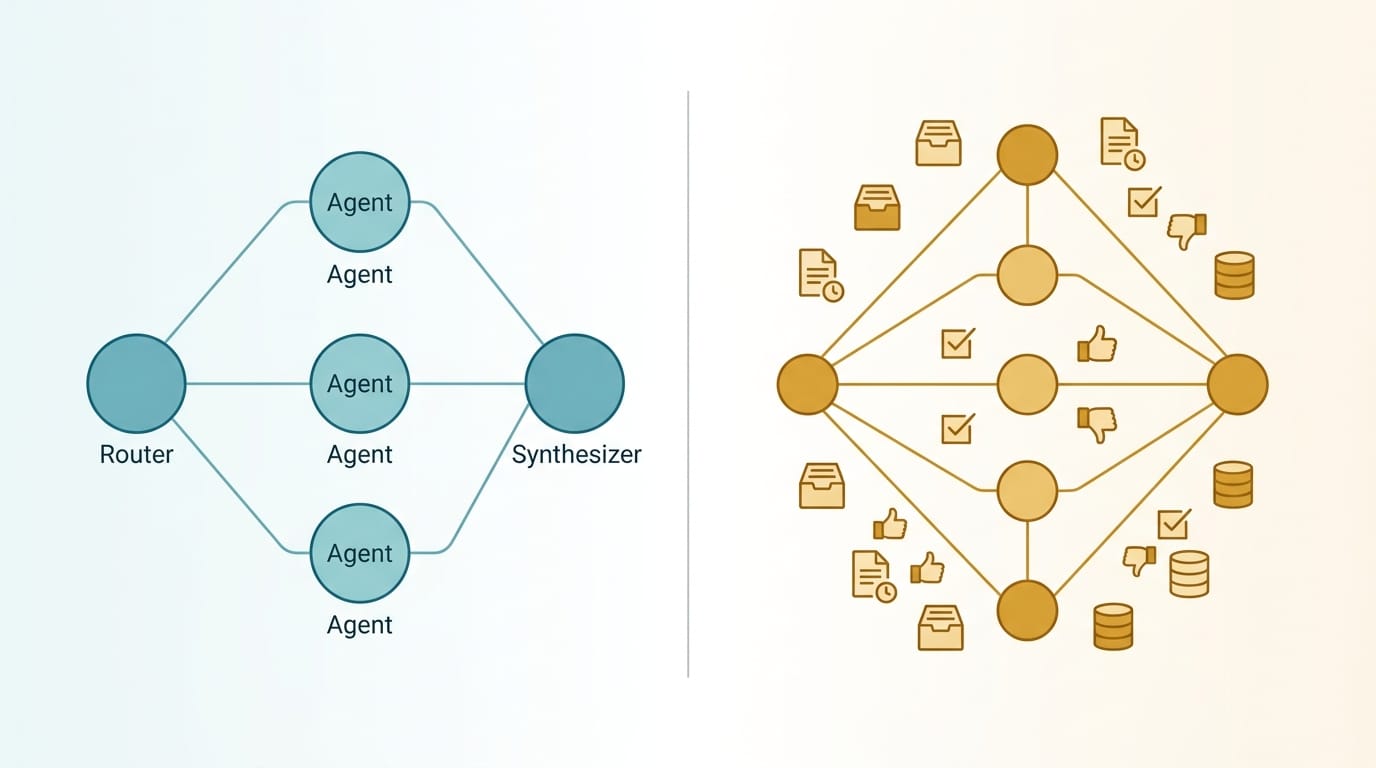
今天看到 Perplexity Max 推出「模型委員會」(Model Council)。它把使用者的 query 同時派給 GPT-5.5 / Claude Opus 4.7 / Gemini 3.1 Pro Thinking 三個模型平行處理,每個模型在獨立的 context 沙箱裡跑,互相看不到對方的輸出。最後由一個 synthesizer 合成最終答案。
我看了一下他們官方的架構說明,第一個反應是笑了。
因為我自己跑了快三個月的「七位一體」AI 協作流程——Claude(Architect)/ Codex(Engineer)/ Gemini(Analyst)/ Perplexity Max(Scout-1)/ SuperGrok(Scout-2)/ gemma4:31b(Local Brain)/ 我自己(Chair)——拓樸幾乎完全一樣。
但繼續往下讀,我意識到這件事的意義不是「我被 Perplexity 抄了」或「業界終於追上了」。
而是一個更有意思的問題:長得一樣的兩個東西,本質可以差非常多。
拓樸幾乎完全一樣
先把表面相似列清楚。
Perplexity Max 模型委員會的核心設計是 Router → Parallel Workers → Synthesizer:
- Router:判斷 query 複雜度,分四級(No Research / Quick / Deep / Comprehensive),不是所有 query 都召開委員會(成本控制)。
- Parallel Workers:多個模型獨立平行處理,互相看不見對方輸出。這是故意的設計——防止 anchoring bias(先看到的答案會 prime 後面的判讀)和 groupthink。
- Synthesizer:另一個模型負責把 N 個輸出合成最終答案。它的職責不是拼接文字,而是解衝突、去重、引用重映射。
Perplexity 自己用模型委員會分析自己的模型委員會(很 meta),三個 thinking model(GPT-5.5 / Claude Opus 4.7 / Gemini 3.1 Pro Thinking)對核心拓樸給出 5/5 共識。
對比我的「七位一體」:
- Chair(我或 Claude)→ 異質 agents → Architect Synthesis
- 七位 agent 互相不可見,必須走 chair-mediated routing(中間人協調)
- Synthesis 階段引用 evidence ID(E1, E2, E3...),不引用 agent 名字(避免「因為 Codex 這樣說所以這樣做」的 ad hominem)
- Router 對應「四層北極星」決策濾網,判斷「這個任務需要召集幾位 agent」
5 個拓樸特性,5 個一樣。這不是巧合。這是 multi-agent fan-out/fan-in 在 2026 年已經收斂到的 SOTA 形狀。
當業界 SOTA 跟你的個人實踐長得一樣,你就知道你走在主流上。但這也意味著——單純拓樸層級的領先優勢消失了。
但這不是 Debate,那才是
讀到一半,Perplexity 自己的三個 thinking model 在一個地方分歧很大:這個架構到底是 Debate Loop 還是 Parallel Sampling?
Claude Opus 4.7 Thinking 的判斷最直接:
「這不是 Debate Loop,就是 Parallel Sampling + LLM-as-Aggregator。類似 Self-Consistency 的跨模型版本,或 Together AI 的 Mixture-of-Agents 第一層。」
換句話說,Perplexity 模型委員會的本質是 「多模型平行抽樣,再用一個模型做最後總和」。模型之間沒有真的辯論、沒有反駁、沒有來回 critique。只是收集多個獨立答案。
這個定性很重要。因為它讓我清楚看到,我做的「七位一體」剛好是另一件事。
七位一體的核心不是 Parallel Sampling,是 Council Protocol——
當一個決策被判定為 high risk(不可逆變更、跨系統邊界、治理規則修改),必須觸發 Mandatory Dissent:Codex 作為 Default Dissenter,要從工程角度寫出結構化異議(含 Assumptions / Evidence / Risks / Trade-offs / Rollback Plan)。沒有異議,就直接 BLOCK 這個決策,不給通過。
這跟 Perplexity 的 Parallel Sampling 是兩種完全不同的哲學:
- Parallel Sampling:相信「多個獨立答案的平均比單一答案準」(ensemble learning 的核心信念)
- Mandatory Dissent:相信「沒有反對意見的決策就是有問題」(治理協定的核心信念)
前者解決的是 「答案品質」。後者解決的是 「決策可審計性」。
如果你的 use case 是「用最快速度給使用者一個高品質答案」,Parallel Sampling 是對的。
如果你的 use case 是「重要決策後 6 個月還能回頭驗證假設是否成立」,Mandatory Dissent 是對的。
兩個工具,兩個目標。
真正的差別:他們不寫 decision log
但最讓我笑的差別在這。
我盯著 Perplexity 那份「模型委員會分析自己的模型委員會」的 doc 看了一陣子,發現一個事實:
他們做完就丟了。
那份分析裡有 Where Models Agree、Where Models Disagree、Unique Discoveries 三個結構,三個 thinking model 給出非常細的觀察(包括 GPT-5.5 Thinking 提的 Evidence Store 結構化設計、Tool Broker 中間層,這些都是漂亮的 production-grade 設計)。
但這份 doc 不會變成 decision。沒有 review_date。沒有 rollback condition。下次他們再開一次模型委員會分析自己,可能跑出完全不一樣的結論——而且他們不會知道,因為沒有對照基準。
我的七位一體不是。每個被七位一體討論過的決策,都會經過一個 lifecycle:
Arena 討論(暫時的)
↓
Staging Area(候選決策,含 Proposal Contract)
↓
Mandatory Dissent(Codex 結構化異議)
↓
Chair Ratify(我親自簽核)
↓
Decision Log(DEC-XXX,永久紀錄)
↓
Review Date(6 個月後驗證假設)
↓
若假設破滅 → Postmortem 寫進 Experiments Log
這套東西工程上不複雜,但需要持續紀律。每個 session 結束都要決定哪些觀察沉澱進長期記憶,哪些只是當下對話。每個決策都要寫出可驗證的假設(不只是「我覺得這樣比較好」)。
換個說法:Perplexity 的「委員會」是 query-time,七位一體的「Council」是 lifecycle-time。
前者解決一次性問題。後者建立一個持續演化、可審計、可挑戰的個人決策系統。
兩者的差距,就是 ensemble 跟 governance 的差距。
為什麼我覺得這 ok
當你看到業界巨頭跟你做一樣的事,自然會想:「我是不是該開始緊張?」
我前幾天剛好在分析自己的七位一體領先窗口。把它分成三層看:
L1 Substrate(agent 怎麼互相通訊):
我用 CLI + 檔案 I/O,這層業界 SaaS 早就超車(LangGraph / AutoGen / Anthropic Agent SDK 等成熟一年以上)。我已經落後 12-18 個月。
L2 Multi-vendor routing(多供應商分工):
我有七家不同 vendor 各自的主戰場規則,業界正在追上(A2A protocol 一年多、Perplexity 模型委員會剛出)。我領先 6-12 個月——窗口正在關閉。
L3 Governance + Memory(治理層與記憶系統):
Risk classification、Council Protocol、Mandatory Dissent、provenance(資料來源分級:raw / llm-derived / human-confirmed)、EPSS(每個 worker 啟動時 context 不含其他 worker 的錯誤)。這些東西在 personal-scale 幾乎沒人在做。我領先 18-30 個月。
Perplexity 模型委員會的出現,正好驗證 L2 那一層在被商品化中。但它不會做 L3——因為 L3 對 SaaS 不友善:
- Risk classification 會降低使用量、增加阻力
- Mandatory Dissent 會讓使用者覺得「為什麼要看反對意見」
- Decision log 是個人責任、無法 SaaS 化
- Provenance 跟業界普遍「越通用越好」的 LLM 設計衝突
換句話說:business model 決定了什麼會被做、什麼不會。
SaaS 的商業模式逼著他們做 ensemble(提升 answer quality 是 KPI),但不會做 governance(個人決策可審計性無法收費)。
而 governance 正好是個人 PKI(Personal Knowledge Infrastructure)的護城河。
給也在做 multi-agent 的人
如果你也在搞個人 multi-agent 工作流——不管是用 LangGraph、CrewAI、AutoGen 還是自寫 broker——我從這次比對得到三個 takeaway 想分享:
1. 拓樸不是你的戰場
Router → Parallel Workers → Synthesizer 是 SOTA。如果你現在還在糾結「要不要平行 / 要不要 chair-mediated / sub-agent 該不該互相可見」,直接抄 SOTA 就好。沒爭議的部分不要重新發明。
具體:
- sub-agent 必須互相不可見(防 anchoring)
- synthesizer 職責是解衝突,不是拼接文字
- router 必須有複雜度分級(不是每題都召集全員)
2. 你真正的 differentiator 在 governance 層
如果你要做的是「持續累積、可審計、可挑戰」的個人決策系統,光複製 Parallel Sampling 不夠。你需要:
- Risk classification:判斷哪些決策需要更高層級的 protocol
- Mandatory Dissent:強制至少一個 agent 提反對意見
- Decision log + Review date:把決策變成可審計事件
- Provenance tier:分清楚哪些資訊是原始、哪些是 LLM 推論、哪些是你親自確認
這些東西工程上不難,難的是紀律——每次都要做,每次都要寫。
3. SaaS 不會做 L3,這是好事
業界 SaaS 會持續壓縮 L1 + L2 的個人化空間。但 L3 是商業模式逼著他們不做的部分。
換句話說,如果你願意花三個月時間建立個人化的 governance + memory + provenance 系統——你做的事情,業界永遠不會給你。
這就是個人 PKI 的長期價值所在。
收尾
回到開頭那個發現的時刻。
我看到 Perplexity 模型委員會時笑出來,不是因為「他們抄我」(人家是 4 億 valuation 的公司,不會抄個人 blog 寫的工作流)。也不是因為「我被超車」(拓樸層級早就被超了)。
我笑的是另一件事——當業界 SaaS 跟你做的事在拓樸上完全一樣,但你心知肚明你做的是另一件事,那種「啊,原來 governance 真的不會被 SaaS 化」的確認感。
L3 仍然是我的,至少還有 18 個月。
夠寫三個月的東西、夠把這套紀律繼續傳遞下去、夠讓我用這套東西做更難的決策。
這篇文章本身就是我七位一體流程的產物。每個觀察、每個 evidence ID、每個對比,都在 staging area 經過 Codex / Gemini / Perplexity Max / SuperGrok 的獨立檢視,再由我(Chair)親自 ratify。
如果你想看完整的決策過程:STG-029 / DEC-XXX 還在 staging,等 Verify Round 2 Scout 回來才會 ratify 到 decisions.md。但我已經把這篇 blog 草稿寫進
agent-council/2026-05-01-agent-team-substrate/,跟 verdict.md 並列。因為寫一篇關於七位一體的 blog,本來就應該被七位一體流程治理。
2026-05-01 寫於台北,七位一體 session 中段。