AI 審查自己,比等著被審查靠譜
AI 生成程式碼的風險不在模型有多強,而在輸出後沒有防線。讓 AI 自己檢查自己,比期望人工 review 來得更實際。

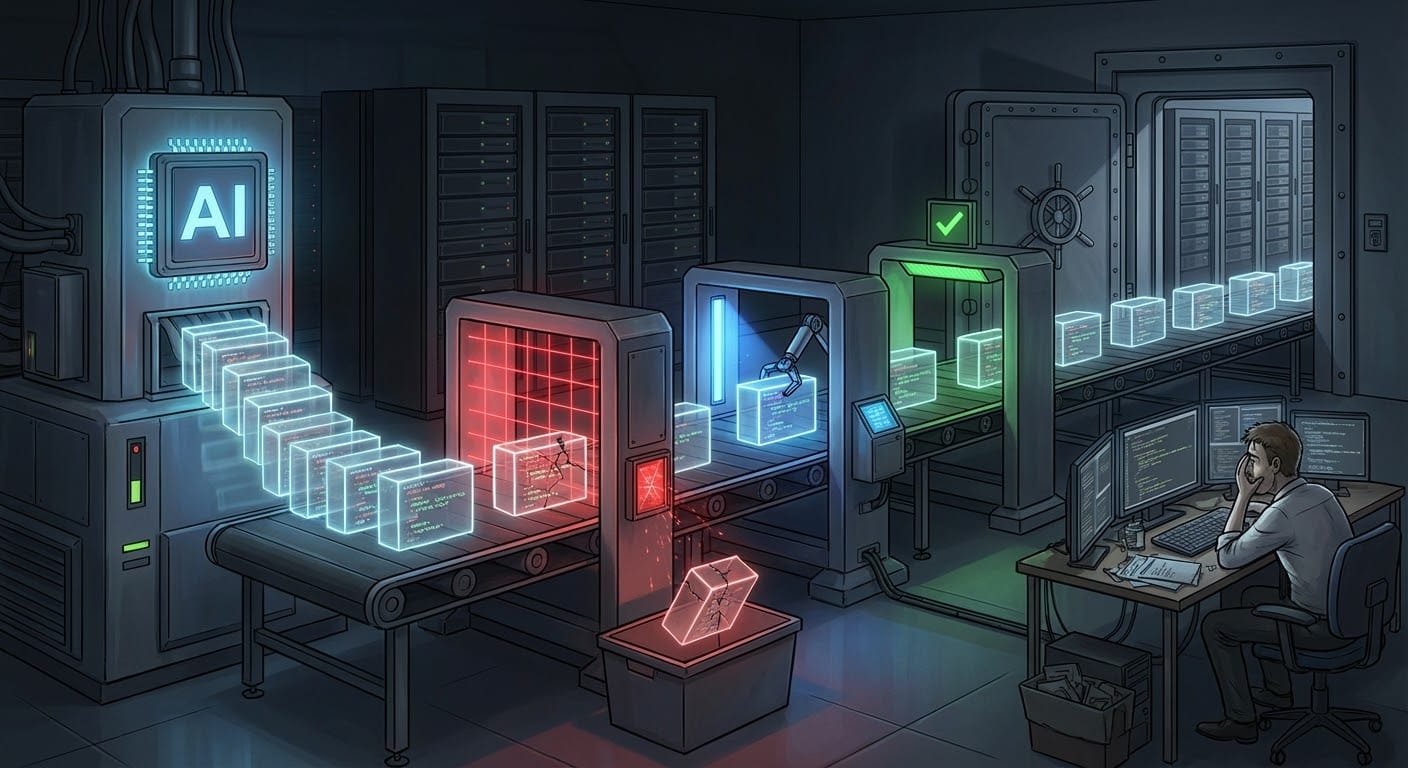
問題不在模型,在輸出後的失控
用 AI 寫程式碼已經不是新鮮事。但真正的風險不在模型本身有多聰明,而在於生成的代碼進入生產環境後,沒有人知道它會做什麼。
你可能會說「我們有 code review」。但坦白講,讓人類 reviewer 逐行檢查 AI 生成的程式碼,本質上是一場體力戰。尤其當代碼量大、邏輯複雜時,人眼掃過去,該發現的問題照樣漏掉。
自審機制:模型自己找自己的漏洞
更務實的做法是讓 AI 在輸出前就開始自我檢查。這不是什麼新概念,但在程式碼生成這個場景裡,它變得特別實用。
具體怎麼做?模型生成代碼後,再用另一個檢查流程(可以是同一個模型,也可以是專門的檢查模型)來驗證:
- 這段代碼會不會有明顯的邏輯錯誤
- 有沒有常見的安全漏洞(SQL injection、buffer overflow 之類)
- 依賴的函式庫版本是否匹配
- 命名規範、型別標註是否一致
關鍵是:這個檢查流程本身不需要完美。它只需要比人工 review 更一致、更快、成本更低。
為什麼這條路線比較靠譜
有些團隊的想法是「我們用更強的模型就能減少錯誤」。這個思路有問題。更強的模型確實能生成更複雜的代碼,但複雜度越高,人工審查的難度就越高。你最後還是卡在同一個瓶頸上。
反過來,自審機制的好處是:
- 可重複:同樣的檢查規則每次都執行,不會因為 reviewer 疲勞而放水
- 可量化:你能看到「通過自審的代碼」和「被標記有問題的代碼」的比例,逐漸調整檢查標準
- 可組合:多層檢查堆疊在一起,風險逐級降低
這更像是在建立一個防線,而不是靠單一的把關者。
實際的問題是什麼
當然,自審機制也有成本。最直接的是延遲——生成代碼後還要再檢查一遍,速度會變慢。還有準確性的權衡——你的檢查規則設得太嚴,會拒絕掉很多其實沒問題的代碼;設得太鬆,就失去了防線的意義。
但這些都是可調的參數。比起「賭一個更聰明的模型」,這至少是在可控的範圍內做權衡。
我現在的看法是:如果你要在生產環境用 AI 寫程式碼,不先建立自審機制就上線,那你不是在做工程,你是在賭博。
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。