AI 反向圖靈測試:當人類開始學著用 AI 的方式說話 反向圖靈測試表面是個遊戲,背後卻映照出一個趨勢:為了讓模型聽懂,我們正在改造自己的表達方式。學會在『像 AI』與『像人』之間切換,會成為新時代的溝通能力。
AI AI 也能寫程式之後:工程師的價值會往哪裡移動 AI 正在把軟體工程拆成可調度的生產線:從副駕到 agent,再到 AI 管 AI。當寫程式變便宜,稀缺的是拆解、驗收、風險控制與對結果負責的能力。
AI Agent Teams 上線後:你不必當傳令兵,但仍要當總工 Agent Teams 的價值不在多開幾個分身,而在更好的協作與訊息路由。Team Lead 仍然必要,因為你要負責決策、邊界切分、合併策略與驗收門檻。
xcode Xcode 26.3 出現後,IDE 的角色正在變 Xcode 26.3 RC 1 已出現在官方下載清單上,更值得注意的是社群開始用『agentic workflow』來談 IDE。工具角色從編輯器走向流程編排,會改寫團隊的協作節奏與品質責任。
AI AI Integration Specialist:企業真正缺的,往往是把 AI 放進現場的人 AI 工具爆炸式成長的同時,企業真正缺的不是更多工具,而是能把 AI 推進到流程現場、形成組織能力的整合角色。
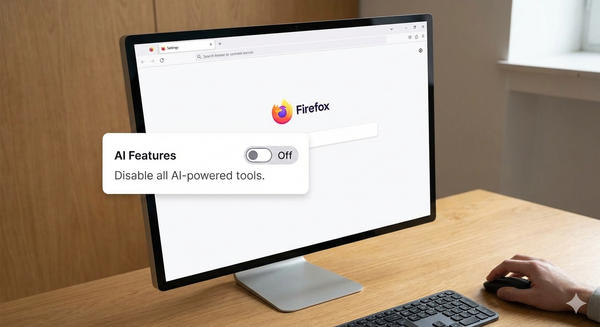
產品思維 Firefox 148 的『AI 總開關』:真正的隱私感,是你可以一鍵拒絕 當 AI 變成產品標配,差異點反而回到『可控』:可關、可見、可管。Firefox 148 的 AI 總開關,把選擇權完整交還給使用者。
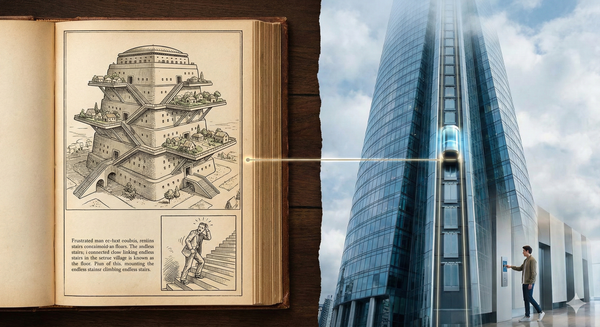
AI AI 的『電梯效應』:我們可能都在用舊問題想像新世界 艾西莫夫的『電梯效應』提醒我們:很多看似合理的推論,只是建立在當下成本結構之上。一個關鍵技術出現,就能推翻整套想像。AI 的討論也可能正在經歷同樣的認知斷層。
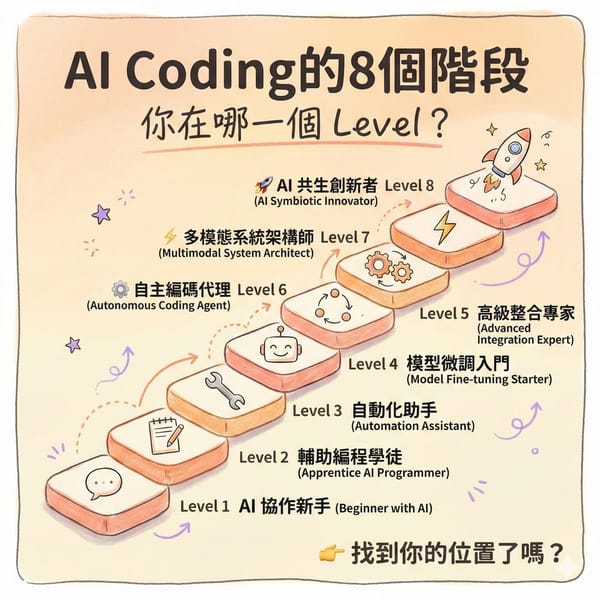
AI AI Coding 的 8 個階段:真正的分水嶺在能不能交付 我把『AI Coding 的 8 個階段』當成成熟度模型來用:從答案、流程到可委派的交付。真正的分水嶺不在 prompt,而在流程、驗證、整合與治理,能不能把產能做成可維運的系統。
AI AI Agent 的硬體入口戰:誰能握住『行為資料』,誰就有下一代平台 AI 正從『內容智能』走向『行為智能』,硬體入口成為新的主戰場。誰能穩定取得情境訊號並交付結果,誰就更可能握住下一代平台主導權。
AI AI 讓「上班」成為選擇?我比較相信:它先讓「時間 ↔ 產出」的比例失真 AI 讓上班成為選擇,往往不是因為大家不用工作了,而是時間與產出開始失去線性比例。當一人+AI 能放大產能,制度與分配機制卻還沒跟上,選擇權會先不均勻地出現在少數人身上。
AI 指揮 Claude Code 打大型戰:把它當成「CEO + 工程師 + QA」的接力賽 大型複雜任務不是靠更長的 prompt,而是靠工作流治理:介面先於實作、分身接力而非平行亂改、每段都要有可驗證的證據,再加上標準化交接包,讓 Claude Code 像一個可控的團隊而不是全能聊天機器人。
AI AI 時代的「倉鼠輪」:你不是不夠努力,你只是缺少一個停下來的判斷框架 每天一個新工具、每天一個顛覆,你不是不夠努力,而是缺少停下來的判斷框架。本文用 3 個問題與 1 input→1 output 的配額制,把『想學』跟『該學』分開,從追新焦慮回到可交付的節奏。
科技趨勢 科技的鐘擺:為什麼運算總在「集中 ↔ 分散」之間來回? 大型主機、PC、雲端、AI GPU 超級資料中心——運算反覆在集中與分散間擺盪,本質是在交換效率與自由。AI 時代算力更集中,但上下文在終端,2030 後更可能走向雲端+終端的混合式運算。
AI 「經驗在演算法面前一文不值」其實是錯題:你該重新定義「經驗」的單位 AI 十分钟写出更优算法,不代表经验一文不值;被压缩的是产出速度,真正稀缺的是判断:目标、约束、验证、代价与风险。经验的计价单位从“记得更多”变成“看得更对”。
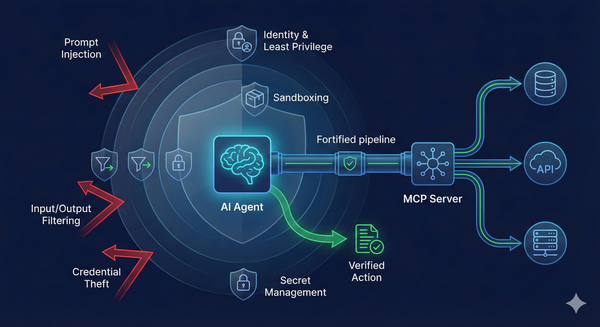
AI AI Agent 越來越強,但你的 MCP 架構扛得住嗎? 最近看到 Google Cloud Tech 談 MCP(Model Context Protocol)安全的影片,裡面有一句話我很認同:當模型開始有「手腳」,你要治理的就不只是模型輸出,而是整個行動鏈。 https://www.youtube.com/watch?v=qGCdbAn0nk8 很多團隊把 MCP 當成「讓 LLM 連接外部工具的標準介面」。工程上它確實很漂亮:代理(Agent)負責決策,MCP Server 負責執行工具操作。但安全上,它等於把攻擊面從「文字」擴大成「能改你系統狀態的一連串動作」。 這篇我用實務角度整理 MCP 架構常見的四類風險,跟一套比較像工程的防線設計:縱深防禦(Defense in Depth)。 ## MCP 的核心風險:
AI 演算法真的比你更懂你嗎?把「洗腦」講得更精準一點 很多人談到推薦系統或 AI 個人化時,會用一句話總結:演算法比你更懂你。 這句話有情緒張力,但如果要把它寫成一篇比較可靠的討論,我更想把問題講得精準一點: 當一個系統長期觀察你的行為,它確實可能建立一套「你會被什麼吸引、會被什麼激怒、會在什麼時候下決定」的模型。 這不等於它能讀心,也不等於你會被完全控制;但它足以影響你每天的注意力分配與資訊飲食。 ## 真正該怕的不是「魔法」,是「長期的微小推動」 影響一個人的想法,很少是一次性的劇烈改造。 更常見的是長期、細碎、近乎無感的改變: * 你看見哪些議題、看不見哪些議題 * 你被推送哪一種框架的敘事 * 你在情緒高點時接收到什麼內容 * 你被鼓勵加入哪些群體、排斥哪些人 如果系統的目標是「讓你停留更久、互動更多」,它自然會找到最能觸發你反應的內容。 而當這種「觸發」被做得足夠個人化,你就會開始覺得:這些內容好像特別懂我。 ## 從產品角度看,這其實是心理建模(psychological profiling) 不用把它講成陰謀論,它比較像一種高強度的行為模型: * 你點什麼、停留多久