RAG 的選擇不是技術問題,是資源問題
Agentic RAG 不是技術進步,是資源消耗。選它之前,先確認你有足夠的預算和清晰的領域邊界。
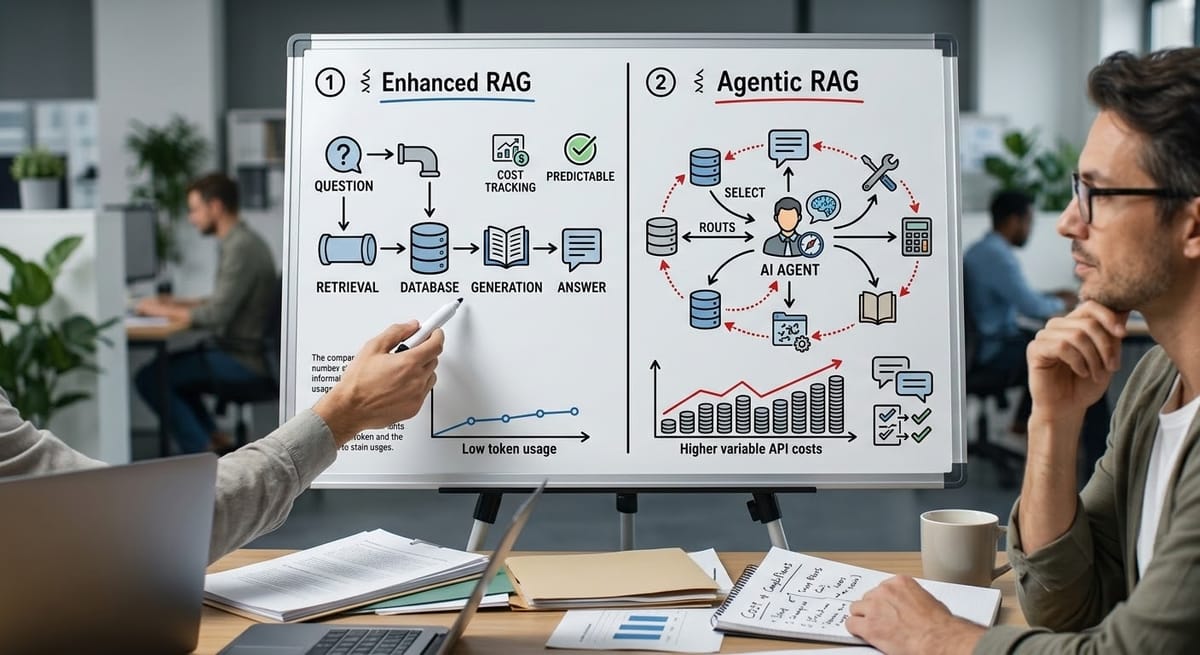
先問兩個問題,再決定架構
我最近在看 RAG 系統的選型,發現很多討論都掉進同一個坑:把 Agentic RAG 當成「更先進」的方案,然後不問成本就往上堆。
但實際上,選 Enhanced 還是 Agentic,根本不是技術優劣的問題。是你有沒有足夠的資源和清晰的領域邊界。
資源充足 + 領域清晰 = Agentic
Agentic RAG 的核心是讓 AI 代理動態決策:選哪個資料庫、調用哪些工具、怎麼組合檢索結果。這聽起來很聰明,但代價是什麼?
- 更多的模型調用:每次查詢不是一次 LLM 推理,而是多輪對話。Token 成本直接翻倍或更多。
- 更複雜的系統:你需要定義清楚代理能用什麼工具、怎麼選擇。這意味著你對領域有足夠的理解,能預定義這些邊界。
- 更難除錯:當結果不對,你要追蹤 AI 的決策路徑,而不只是檢查一個檢索管道。
什麼時候值得付這個代價?當你的任務夠複雜,需要跨多個資料源、多步推理;當你的領域邊界清晰,能明確定義代理的工具集;當你的預算允許更多的 API 調用。
換句話說:你要有錢,也要有把握。
反過來就用 Enhanced
Enhanced RAG 是模組化的流水線:檢索 → 過濾 → 排序 → 生成。每一步都是確定的規則或簡單的 LLM 調用。
它的優勢是什麼?
- 成本可控:一次查詢就是一次檢索 + 一次生成,Token 用量清楚。
- 可預測:因為流程固定,你能更容易地測試和改進每一個環節。
- 對開放域任務更穩定:當領域邊界不清楚時,固定流程反而比 AI 自主決策更靠譜。
但它的瓶頸在文件篩選。如果你的檢索結果品質差,後面再聰明也救不了。所以 Enhanced 的關鍵投資點應該在:改進向量模型、優化文件分塊、建立更好的重排序邏輯。
實際的判斷框架
我現在是這樣看的:
先用 Enhanced 做一個基線。測量它的檢索精準度和生成品質。如果瓶頸在「系統不知道該用哪個資料源」或「需要多步推理」,再考慮升級到 Agentic。
不要反過來。不要因為看起來更智能就先選 Agentic,然後發現成本爆炸、效果也沒好多少。
我也見過一些團隊用 Agentic 但定義得很差——代理的工具集太多,反而增加了決策難度。這時候不是 Agentic 的問題,是你沒有真正理解自己的領域。
一個細節
Enhanced 和 Agentic 不是非此即彼。有些系統會在 Enhanced 的檢索步驟中加入輕量級的代理邏輯——比如根據查詢類型動態選擇檢索策略,但不讓 AI 完全自主決策。這是一個中間態,值得試試。
最後一句:技術選型的本質是權衡。Agentic RAG 很酷,但酷不等於適合你。問清楚自己有什麼資源、面對什麼問題,答案就出來了。
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。