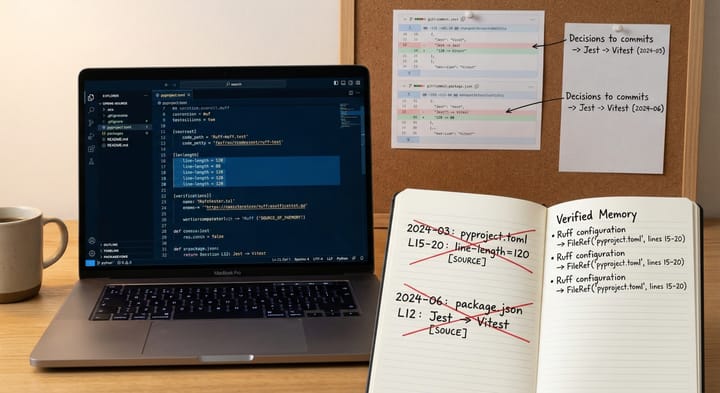
我把 memcite 裝進自己的專案,記錄下真實的數字

我把 memcite 裝進自己的專案,記錄下真實的數字
上一篇我介紹了 memcite 的設計理念:AI agent 的記憶需要出處,出處需要被驗證。
理念很好。但真的有用嗎?
這篇是導入心得。我把 memcite 裝進一個 6,000 行的 Python 專案(mk-brain,我的個人知識管線),從安裝到測試,完整記錄每一個數字。
導入:零侵入,52KB
pip install memcite
cd ~/GitHub/mk-brain
am add "6 層 pipeline:Parse → Review → Enrich → Embed → Report → Search" \
--file README.md --lines 9-26
裝完後專案裡多了一個檔案:.agentic-memory.db(52KB)。沒有改動任何既有 code,沒有新增 dependency 到專案本身,沒有動 CI。
我用 CLI 模式操作,不在專案的 venv 裡裝 memcite — 完全旁掛。想移除的話,刪掉那個 52KB 的檔案就結束了。
我花了大約 5 分鐘,建立了 6 條核心記憶:
| 記憶 | 引用來源 |
|---|---|
| Pipeline 架構(6 層) | README.md L9-26 |
| 9 維 LLM 評分引擎 | scoring.py L1-60 |
| Model Gateway 路由規則 | model_gateway.py L1-32 |
| 共用 DB 模組 | db_utils.py L1-30 |
| Embedding + Hybrid Search | AGENTS.md L37-55 |
| 系統需求 | README.md L55-67 |
測試一:能不能找到答案?
不裝 memcite 的話,新 session 的 AI agent 要回答「這個專案的評分用什麼 LLM?」,需要先 grep、再 read 檔案、再解析 — 通常 2-3 次 tool call,花幾秒鐘。
裝了之後:
$ am query "評分用什麼模型"
1. scoring.py 使用 9 維 LLM 評分(v4.0)...由 DGX Spark 上的 qwen3.5:9b 執行。
✓ scoring.py L1-60 [valid]
confidence: 1.0
0.077 秒,一次呼叫,直接拿到答案 + 來源 + 驗證狀態。
5 個中文查詢全部命中:
| 查詢 | 結果 | 耗時 |
|---|---|---|
| 評分用什麼模型 | scoring.py — qwen3.5:9b | 0.077s |
| search 的權重比例 | hybrid search — dense 70% + sparse 30% | 0.077s |
| embedding 維度 | bge-m3, 1024d | 0.077s |
| gateway 路由規則 | vLLM vs Ollama 路由表 | 0.077s |
| pipeline 有幾層 | 6 層 pipeline 架構圖 | 0.077s |
但這只是 memcite 的基本功。真正的殺手功能是下一個測試。
測試二:改了 code,記憶知道嗎?
這是 memcite 和其他記憶工具的本質差異。
我故意改了 scoring.py,把 LLM model 從 qwen3.5:9b 改成 qwen3:32b(模擬真實的版本升級)。
$ am validate
✓ 5 valid
⚠ 1 stale
Problematic memories:
⚠ scoring.py 使用 9 維 LLM 評分...qwen3.5:9b
Content changed at scoring.py L1-60
抓到了。 memcite 偵測到被引用的檔案內容改變,把那條記憶標記為 STALE。
更關鍵的是 query 行為的變化:
$ am query "scoring"
1. db_utils.py... ✓ [valid] confidence: 1.0 # 沒改的排前面
2. scoring.py... ⚠ [stale] confidence: 0.2 # 改過的降權
confidence 從 1.0 降到 0.2,排序也自動降級。Agent 不會被過期的記憶誤導。
還原檔案後再跑一次 validate:全部恢復 valid。整個過程是自動的,不需要人工介入。
如果你用 mem0 或其他記憶工具,這條記憶會安靜地待在那裡,繼續告訴你的 agent「model 是 qwen3.5:9b」—— 即使它已經不是了。
測試三:會不會被錯誤記憶誤導?
我故意加了一條錯誤記憶:「mk-brain 只支援 dense search,不支援 hybrid search」(實際上支援)。
$ am query "search hybrid"
1. mk-brain 只支援 dense search... ✓ [valid] confidence: 1.0 # 錯的排第一
2. Embedding... hybrid search... ✓ [valid] confidence: 1.0 # 對的排第二
這是 memcite 目前的限制: 它驗證的是「引用來源是否還在」,不是「記憶描述是否正確」。如果你指向一個存在的檔案,但寫了錯誤的描述,memcite 抓不到。
換句話說:垃圾進,垃圾出。 記憶的品質取決於寫入的人(或 agent)。
這也是為什麼 memcite 提供了 Admission Control — 你可以在寫入前做品質檢查,用規則或 LLM 過濾掉模糊、空洞的記憶。
測試四:開銷
| 指標 | 數值 |
|---|---|
| DB 大小(6 條記憶) | 52 KB |
| 單次 query | 0.077s |
| 全量 validate(6 條) | 0.073s |
| 新增 dependency | 0(CLI 旁掛模式) |
| 改動的既有檔案 | 0 |
唯一改動的是 .gitignore 加了一行 .agentic-memory.db。
我的結論
| 維度 | 評價 |
|---|---|
| Staleness Detection | 獨一無二的價值。改了 code 記憶就知道。 |
| 查詢速度 | 0.077s,比 grep+read 快一個數量級 |
| 侵入性 | 零。刪掉一個檔案就完全移除 |
| 中文支援 | v0.4.1 起完全可用 |
| 內容正確性保證 | 不驗內容,只驗引用。需搭配 admission control |
如果你在做任何跟 AI agent 相關的開發,花 5 分鐘試一下:
pip install memcite
cd your-project
am add "你的專案用什麼測試框架" --file package.json --lines 10-15
am query "test framework"
然後去改 package.json 的那幾行,再跑 am validate。
你會看到它亮起黃燈。
那個黃燈,就是你的 agent 在其他記憶工具裡不會收到的警告。
- GitHub: MakiDevelop/agentic-memory
- PyPI:
pip install memcite - 前一篇:從「能記住」到「能審計」:為什麼 AI 記憶層需要 Source Code 級歸因
我是江中喬,目前專注於 AI 認知增強系統的設計與實踐。這篇文章的測試數據全部來自真實專案,沒有捏造。