從「能記住」到「能審計」:為什麼 AI 記憶層需要 Source Code 級歸因
GitHub Copilot 在 2025 年底推出了 Memory 功能。它會記住你的 repo 慣例、coding style、常用 pattern,下次寫 code 時自動套用。
這是一個正確的方向。但它是閉源的。
所以我做了一個開源版:memcite。
但這篇文章不是要推銷工具。我想聊的是一個更根本的問題:為什麼現有的 AI 記憶層都在解決錯的問題?
所有人都在解決「記住」,沒人在解決「記對」
打開任何一個 AI memory layer 的 README,你會看到類似的 pitch:
- mem0:「讓 AI 記住使用者偏好,跨 session 持續學習」
- Zep:「時序知識圖譜,知道事情發生的先後順序」
- LangMem:「過程記憶,讓 agent 從失敗中學習」
這些都是好東西。但它們有一個共同的盲區:
存進去的記憶,三個月後還是對的嗎?
當你的 agent 記住「這個專案用 Jest 測試」,然後團隊在某次重構中換成了 Vitest —— agent 不知道。它會繼續自信地用 Jest 的語法寫測試,自信地搞壞你的 CI。
這不是幻覺(hallucination),因為這條記憶「曾經」是對的。這是比幻覺更危險的東西:過期的事實,加上 agent 的自信。
我稱它為 Memory Drift(記憶漂移)。
Memory Drift 的三種死法
1. 檔案變了,記憶沒變
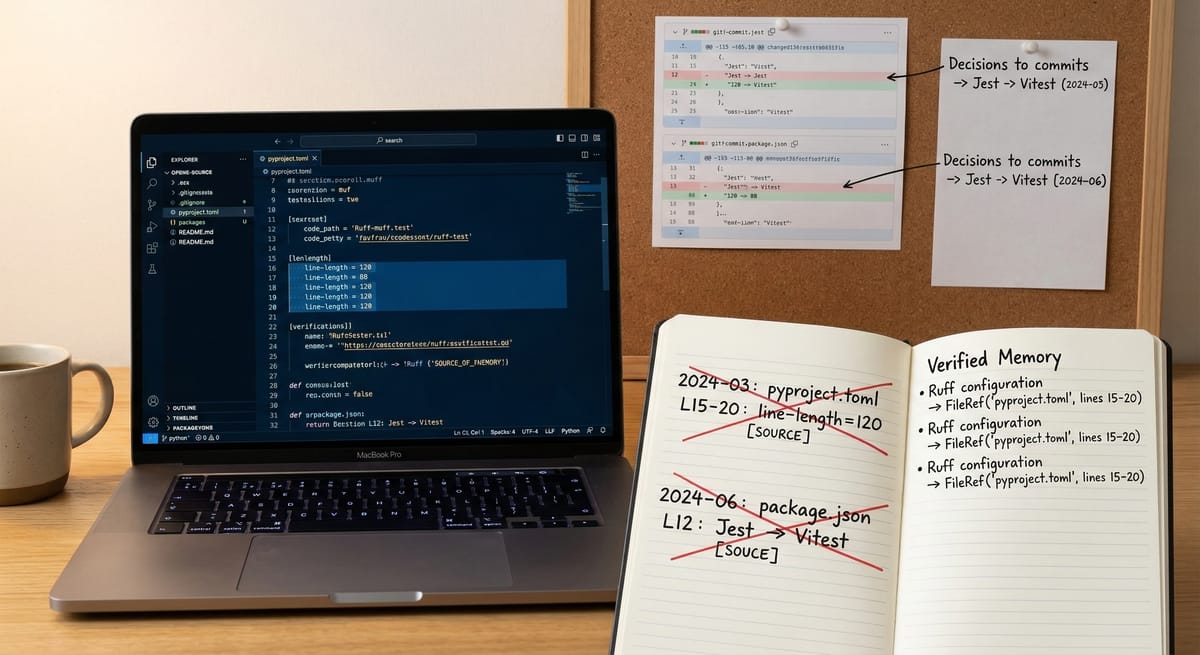
Agent 記住「pyproject.toml 第 15 行設定 line-length=120」。三週後有人改成 88。Agent 下次 review code 還是會說「這裡超過 120 字元了」。
2. 檔案刪了,記憶還在
某個 config 檔在重構中被移除,但 agent 腦中還有一條指向它的記憶。更糟的是,agent 可能會建議「你需要在 config/legacy.yaml 加上這個設定」—— 一個已經不存在的檔案。
3. Commit 歷史前進了,記憶停在原地
Agent 記住某個 PR 的決策:「我們決定不用 Redis,改用 SQLite」。但那是六個月前的決策,後來因為 scale 問題又換回 Redis 了。Agent 不知道。
這三種情況的共通點是:記憶沒有出處,或者出處沒有被驗證。
GitHub Copilot Memory 的正確直覺
GitHub 的團隊在設計 Copilot Memory 時,做對了幾件事:
- Repo-scoped:每個 repo 有獨立的記憶空間,不會跨專案污染
- Citation-backed:每條記憶對應到 repo 中可驗證的來源
- Just-in-time verification:使用記憶前,先確認來源還在
這些設計原則來自一個簡單的洞察:在工程環境中,沒有出處的記憶就是幻覺的種子。
問題是,Copilot Memory 是閉源的。如果你不用 GitHub Copilot,或者你想在自己的 agent 裡實現類似的機制,你沒有選擇。
開源版怎麼做:memcite 的三個設計原則
原則一:No Evidence, No Memory
在 memcite 中,你不能存一條沒有出處的記憶。這不是建議,是強制的。
from agentic_memory import Memory, FileRef
mem = Memory("./my-project")
# 這會成功 — 有出處
mem.add(
"Uses ruff for linting with line-length=120",
evidence=FileRef("pyproject.toml", lines=(15, 20)),
)
# 這會失敗 — 沒有 evidence 參數
mem.add("Uses ruff for linting") # TypeError!
四種 Evidence 類型覆蓋了工程場景的主要來源:
| 類型 | 追蹤什麼 | 驗證方式 |
|---|---|---|
FileRef |
檔案路徑 + 行號範圍 | 檢查檔案存在 + content hash 比對 |
GitCommitRef |
Commit SHA | 確認 commit 在歷史中 |
URLRef |
Web URL | HTTP HEAD 檢查 |
ManualRef |
人工標註 | 永遠信任(人類說了算) |
原則二:Validate Before Use
當你查詢記憶時,memcite 會自動去驗證每條記憶的出處。
result = mem.query("What linter does this project use?")
for memory, citation in zip(result.memories, result.citations):
print(f"{memory.content}")
print(f" Source: {citation.evidence.short_label()}")
print(f" Status: {citation.status.value}")
# 可能輸出:
# Uses ruff for linting with line-length=120
# Source: pyproject.toml L15-20
# Status: STALE ← 檔案內容已經改了!
如果 pyproject.toml 的第 15-20 行內容已經改變,這條記憶會被標記為 STALE。它不會被刪除(也許只是格式改了,內容還是對的),但 confidence 會下降,排序會靠後。
原則三:Decay What's Stale
$ am validate
✓ 42 memories valid
⚠ 3 memories stale (evidence changed)
✗ 1 memory invalid (file deleted)
Stale memories:
- "API rate limit is 100/min" ← README.md L33 changed 5 days ago
- "Uses Jest for testing" ← package.json L12 changed 2 weeks ago
你可以定期跑 am validate,或者在 CI 中加一步,確保你的 agent 不會用過期的知識做決策。
不只是 CLI:四種使用方式
memcite 設計為可嵌入任何 agent workflow:
Python SDK — 三行 code 就能用:
pip install memcite
CLI — 在 terminal 直接操作:
am add "Uses pytest" --file tests/conftest.py --lines 1-10
am query "test framework"
MCP Server — 給 Claude Code 直接用:
{
"mcpServers": {
"agentic-memory": {
"command": "am-mcp",
"args": ["--repo", "/path/to/project"]
}
}
}
REST API — 給任何 agent 透過 HTTP 呼叫:
pip install memcite[api]
am-server --repo ./my-project --port 8080
# OpenAPI docs at http://localhost:8080/docs
混合搜尋:不只是關鍵字匹配
memcite 內建 hybrid search,結合 FTS5 全文搜尋和 TF-IDF 向量相似度:
from agentic_memory import Memory, TFIDFEmbedding
mem = Memory("./my-project", embedding=TFIDFEmbedding())
mem.add("Uses ruff for code formatting", evidence=FileRef("pyproject.toml", lines=(1, 5)))
# 查 "linting" 也能找到存了 "formatting" 的記憶
result = mem.query("What linter does this project use?")
預設零外部依賴(純 numpy),想要更好的語意搜尋可以接 fastembed 或任何 embedding provider。
垃圾記憶不准進:Admission Control
不是所有東西都值得記住。memcite 支援在存入前做品質檢查:
from agentic_memory import Memory, HeuristicAdmissionController
mem = Memory("./my-project", admission=HeuristicAdmissionController())
mem.add("ok", evidence=ManualRef("chat"))
# ValueError: Memory rejected — too vague
mem.add("Uses ruff for linting with line-length=120",
evidence=FileRef("pyproject.toml", lines=(15, 20)))
# 通過 — 有 actionable content + 具體數值
也支援接 LLM 做更智慧的評分,失敗時自動 fallback 到規則版。
跟競品的差異
| mem0 | Zep | LangMem | Copilot Memory | memcite | |
|---|---|---|---|---|---|
| 強制 citation | No | No | No | Yes (閉源) | Yes |
| 來源驗證 | No | No | No | Yes (閉源) | Yes |
| 過期偵測 | No | No | No | Unknown | Yes |
| Repo-scoped | No | No | No | Yes | Yes |
| Self-hosted | Yes | Yes | Yes | No | Yes |
| MCP 支援 | Yes | No | No | N/A | Yes |
結語
AI agent 的記憶層正在從「能記住」進化到「能審計」。
GitHub Copilot Memory 證明了這個方向是對的。但工程社群需要一個開源、可自架、可嵌入的版本。
memcite 就是這個嘗試。71 個測試,MIT license,pip install memcite 就能用。
如果你在做 AI agent,試試看把「記憶來源驗證」加進你的 pipeline。你的 agent 不該自信地引用三個月前的 config 來搞壞 production。
- GitHub: MakiDevelop/agentic-memory
- PyPI: memcite
- Install:
pip install memcite
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。