從程式片段到長程任務:AI Coding 走向『可結案』的門檻
整理一則 Threads 貼文:當工具主打長程技術工作,重點不只在生成程式碼,而在需求界定、整合回歸、可觀測性與可驗證的交付流程。

最近幾個月在看 AI Coding 的產品路線,最常被提到的是「寫得更快」「補得更準」。但有些更新訊號指向另一個方向:工具開始嘗試把自己定位成能承接較長任務的工作單位。
原貼文提到某款工具主打「長程技術工作」,並把這視為 AI 從產出程式片段,往「可獨立結案的 agent」移動。
從片段生成到任務交付,中間差的是什麼
很多團隊的使用經驗大致相似:
- AI 能快速產出一段可用的程式碼
- 但只要任務一拉長,或需要跨模組串接,成果品質就容易不穩
- 架構、整合、測試與收尾仍需要人力投入
因此,「長程」如果要成立,不會只是一句口號,背後需要一套讓成果可驗證、可回收、可迭代的工作方式。
長程任務的關鍵瓶頸(整理)
若把「做完一段 code」與「完成一個可交付任務」分開看,後者通常包含:
- 需求與範圍界定
- 目標是什麼
- 不包含什麼
- 成功條件(驗收標準)是什麼
- 系統與依賴的理解
- 既有架構與介面
- 資料流與權限邊界
- 與其他模組的耦合點
- 整合與回歸驗證
- 會不會破壞既有功能
- 是否覆蓋主要路徑與邊界條件
- 是否需要自動化測試與 CI
- 可觀測性與除錯成本
- 日誌、指標、追蹤(tracing)是否足夠
- 問題出現時能否快速定位
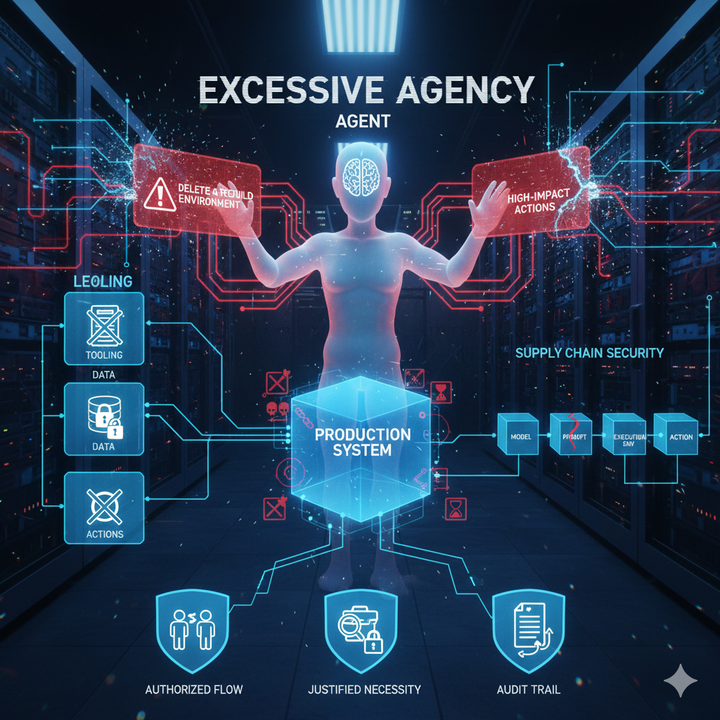
如果沒有這些支撐,任務越長,回頭修正的成本會越高,也更容易出現「前面看起來都對,最後收不了尾」的情況。
以「agent 能結案」做目標時,可以怎麼評估
若工具宣稱能做長程技術工作,實務上可用下列問題做檢核:
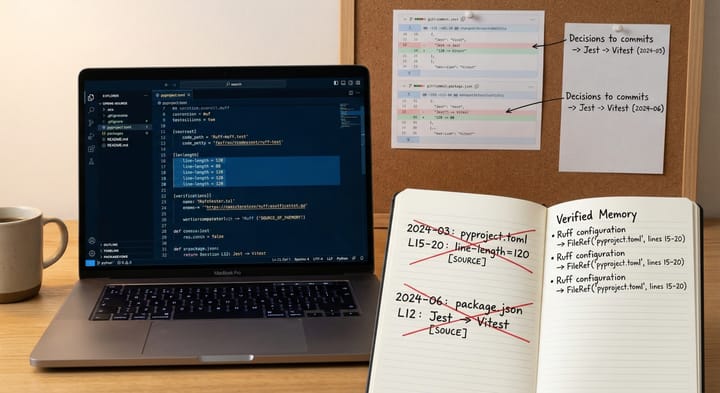
- 是否能在同一任務中維持一致的設計決策(不頻繁改口)
- 是否能在改動後自動補齊測試或至少提出測試建議
- 是否能處理多步驟的整合(例如跨服務、跨資料表、跨權限)
- 是否能在失敗時提供可追溯的原因與下一步(而非重寫一版)
小結
長程任務的價值在於:它把人從「反覆接龍」拉到「設定方向與驗收標準」。
同時,它也會把團隊的工程底座放大檢視:測試、CI/CD、架構邊界、可觀測性是否成熟,會直接影響你敢不敢把任務交出去。