AI Agent 越來越強,但你的 MCP 架構扛得住嗎?
最近看到 Google Cloud Tech 談 MCP(Model Context Protocol)安全的影片,裡面有一句話我很認同:當模型開始有「手腳」,你要治理的就不只是模型輸出,而是整個行動鏈。
https://www.youtube.com/watch?v=qGCdbAn0nk8
很多團隊把 MCP 當成「讓 LLM 連接外部工具的標準介面」。工程上它確實很漂亮:代理(Agent)負責決策,MCP Server 負責執行工具操作。但安全上,它等於把攻擊面從「文字」擴大成「能改你系統狀態的一連串動作」。
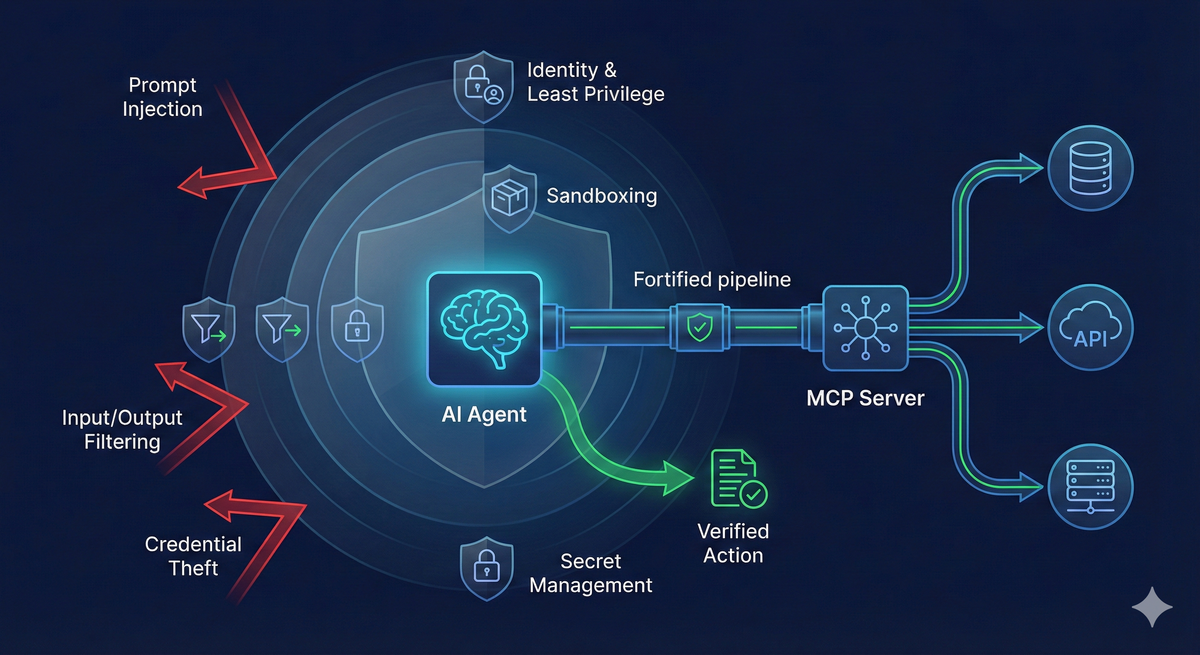
這篇我用實務角度整理 MCP 架構常見的四類風險,跟一套比較像工程的防線設計:縱深防禦(Defense in Depth)。
## MCP 的核心風險:不是連了多少工具,是把權限與行為串起來
在傳統系統裡,工具與權限往往分散在不同服務;在 Agentic AI 架構裡,你開始把「理解指令」與「執行動作」放在同一條工作流。
這會讓資安風險長得更像供應鏈事故:不一定有人正面突破你,而是你自己把一條捷徑鋪好。
## 四大風險(工程版翻譯)
### 1)權限過大(Overprivileged Agents)
最常見也最致命。為了方便,你把 Agent 的權限開到足以讀寫整個資料庫、拿到所有文件、甚至能操作關鍵系統。
一旦 Agent 被誤導,或它的決策被污染,後果會是越權存取與資料外洩。
### 2)Prompt Injection(輸入污染導致行為偏轉)
這是 Agent 系統獨有的麻煩:惡意指令不一定會以「指令」樣子出現,它可能藏在網站內容、文件、工單、Slack 訊息裡。
Agent 讀到之後,把它當成高優先級指令,接著去觸發工具:抓資料、寄出、修改設定。
### 3)憑證遭竊(Credential Theft)
Agent 要做事,通常需要 OAuth token、API key、service account。憑證一旦暴露,你不只失去一個 agent,你是失去一整串系統入口。
這也是為什麼很多事故的本質是「secret management」做得不夠像工程。
### 4)Command Injection / RCE(執行層被打穿)
MCP Server 端如果把工具呼叫做得太直接(例如把字串拼成命令、或對輸入沒有嚴格驗證),就可能被誘導執行任意命令。
這會把風險從「模型做錯事」升級成「伺服器被接管」。
## 防線怎麼設計:縱深防禦,不靠單點神技
我很喜歡「Defense in Depth」這個詞,因為它提醒一件事:你要假設任何單一層都會失守。
### 1)建立唯一的 Agent Identity(可追溯的數位身分)
不要讓所有代理共用同一個帳號。
讓每個 agent 有獨立身分、獨立權限與獨立 audit log,才有辦法做:
- 精準授權
- 事後追查
- 分級風險
### 2)最小權限(Least Privilege)
權限不只是「能不能做」,還包含「做得到多深」。
把權限拆成讀、寫、刪、外寄、執行,並把高風險動作加上人類確認閘門,會讓整個系統可控很多。
### 3)憑證隔離儲存(Secret Manager)
不要把 key 寫死在程式碼或 prompt。
更重要的是:模型本身不應該直接碰到 secrets。它只能透過受控的執行層去完成授權過的動作。
### 4)運行時沙箱化(Sandboxing)
讓 agent 跑在受限環境(容器/Cloud Run/GKE 的受控 namespace)。
目標不是防止它出錯,而是讓它出錯時的爆炸半徑夠小。
### 5)輸入與輸出雙向防護(例如 Model Armor 類思路)
把「進入 agent 的內容」當成不可信輸入,做過濾與分級。
同時把「agent 對外發出的動作」做政策檢查與稽核。真正有效的防護不是只擋 prompt,而是把行為也納入治理。
## 結尾:Agentic AI 的安全,本質是治理能力
MCP 讓 Agent 系統變得更可組裝、更標準化,但安全問題不會因此自動消失。
你能安心用 Agent 的前提,是你能回答這些問題:
- 誰在做事?(身分)
- 被允許做什麼?(權限)
- 內容從哪來?(輸入治理)
- 出事怎麼止損?(隔離與回滾)
- 做過什麼可不可以追?(audit)
當你把這些做成工程,MCP 才會是加速器,而不是引爆點。
#AI #MCP #AgenticAI #資安 #DevSecOps #GoogleCloud