Agent 編碼的擴展單位不是 token,是 Thread
IndyDevDan 提出的 Thread 框架給了 Agent 編碼一個可量化的擴展單位。但大多數人還卡在單 Thread 品質不穩的階段。
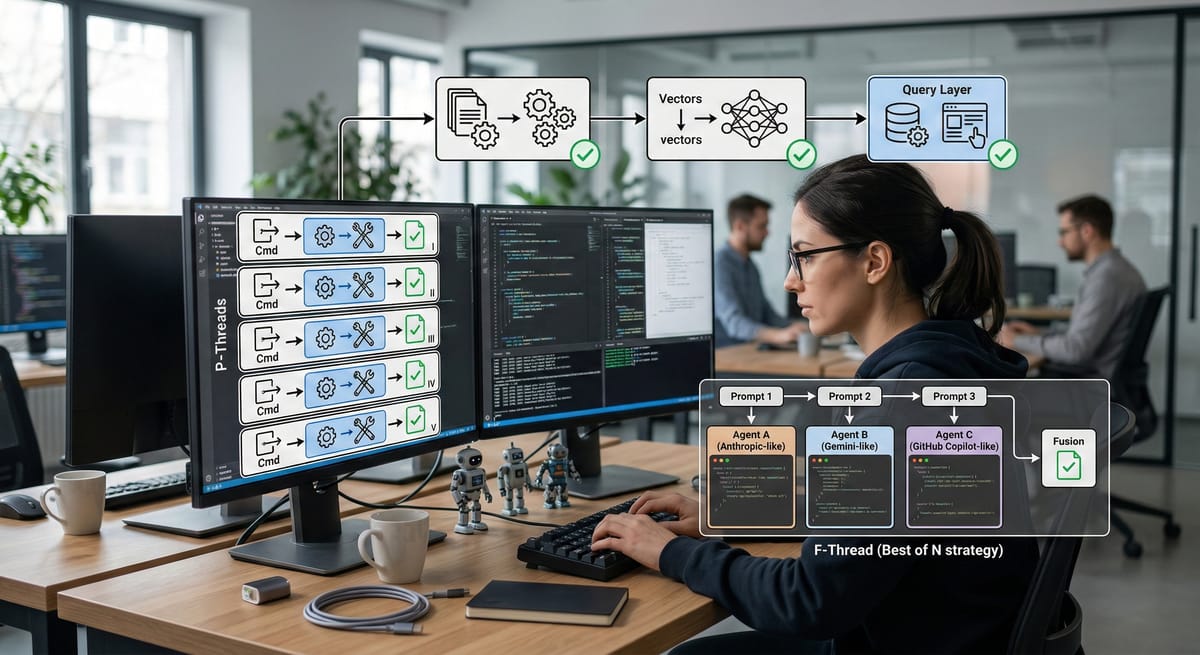
IndyDevDan 提出了一個框架:把 AI Agent 的工作拆解成 Thread——每個 Thread 就是一輪「指令 → Agent 執行(工具呼叫)→ 審查」的循環。每次在終端機敲一次 Enter,其實就是啟動了一條 Thread。
這個框架的價值在於,它給了一個可量化的單位。
為什麼我們需要新的度量方式
過去評估 Agent 的效率,不是看 token 消耗就是看產出速度,但這兩個指標都沒辦法反映真正的生產力。Peter Drucker 早就警告過:"There is nothing so useless as doing efficiently that which should not be done at all." 一個 Agent 消耗了 50 萬 token 但沒有解決問題,跟另一個只用了 5 萬 token 就交付成果的 Agent,用 token 衡量完全分不出高下。
Thread 的數量和品質,比較接近實際的工作產出。IndyDevDan 引用了一句話:"If you don't measure it, you will not be able to improve it."——這句話在 Agent 編碼的場景裡格外準確。當你把每一次「指令→執行→審查」循環當作一個可觀測的單位,你才能開始分析哪些 Thread 有價值、哪些是浪費。
P-Thread(平行):量產的前提是品質穩定
Boris Cherny 在 X 上秀出自己同時開 5 個 Claude Code,外加 5-10 個背景 Session,等於 10-15 條 Thread 平行跑。產出速度自然成倍提升。
但這裡有一個前提很少人強調:如果你連單條 Thread 都得盯著看,開再多也只是製造更多需要審查的東西。這跟 Frederick Brooks 在《人月神話》中的經典論點一樣——增加人力(或 Agent)不等於增加產出,溝通和協調成本會吃掉你以為多出來的效率。
Budget-Aware Tool-Use 的研究驗證了這個直覺:控制工具呼叫的頻率和品質,比單純增加 Agent 數量更能帶來穩定的擴展。換句話說,先把單條 Thread 的指令寫清楚、審查流程標準化,再談平行。
C-Thread(鏈式):高風險任務的安全帶
當任務太大或需要跨階段驗證時,切成多段依序執行,每段結束暫停審查。我在做公司的 RAG 系統重構時就用了這種模式:先讓 Agent 處理 chunking 邏輯,審查確認後再處理 embedding,最後才是查詢層。每個階段都有明確的輸入輸出合約。
這跟 TechCrunch 報導的 APEX-Agents 基準測試結果一致:多階段檢查能顯著降低跨工具協作的錯誤率。Anthropic 自己的 Agent 設計指南也推薦這種模式,他們稱之為「Orchestrator-Worker」——一個控制流程負責拆分任務和品質把關,多個 Worker 負責執行。
F-Thread(融合):多 Agent 把關的版本控制
同一個 prompt 丟給多個 Agent,取最佳結果或融合各自優勢。本質上是 "Best of N" 策略。
這不是新概念。DeepMind 在 AlphaCode 2 的論文中就用了類似的方法——生成大量候選解法,再用一個評估模型挑出最佳答案。把這個思路搬到日常的 Agent 編碼:你讓 Claude、Gemini 和 Codex 各自寫一版,四個裡面有三個給出相同解法,你就有了信心。多版本比較再融合,比單線迭代更能穩定品質。
我的判斷
大多數人——包括我自己——現在還卡在單 Thread 品質不穩的階段。真正能平行跑 15 條 Thread 的人,前提是他們已經花了足夠長的時間打磨單條 Thread 的指令品質和審查效率。這不是捷徑,是基本功。
原始來源:https://blog.aihao.tw/2026/02/28/thread-based-engineering/
我是江中喬,一位具有 TPM 與產品管理背景的 AI 系統建構者,目前專注於 AI 認知增強系統與多 Agent 協作架構的設計與實踐。